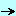|
Bayesian Spam Filter - Felix John COLIBRI. |
- abstract : presentation and implementation of a spam elimination tool which uses Bayesian Filtering techniques
- key words : tutorial - machine learning - text classifier - Bayes - spam
filter - string hash table - iterator - bounded insert sort
- software used : Windows XP Home, Delphi 6
- hardware used : Pentium 2.800Mhz, 512 M memory, 140 G hard disc
- scope : Delphi 1 to 2006, Turbo Delphi for Windows, Kylix
Delphi 5, 6, 7, 8 Delphi 2005, 2006, Turbo Delphi, Turbo 2007, Rad Studio 2007
- level : Delphi developer
- plan :
1 - E-mail Spam Removal Everybody today is annoyed by spam mail or spam web feed back. There are many techniques to reduce this nuisance, and Bayes statistical analysis is one of
the most efficient. This article will present the rationale and a Delphi project implementing a Bayes filter which nearly eliminates spam.
2 - Spam Elimination 2.1 - Spam Definition
We maintain 3 developer web sites, and on on nearly all of our pages we present a direct link to our e-mail address (the <A HREF="mailto:xxx@yyy.zzz"> tag). We therefore receive a big amount of spam every day. We also receive some
legitimate mail from readers wanting to contact us to organize training, comment on our articles or ask for help. The problem is how can we sort those mails in two parts: the spam and the "good" mail. We caracterize spam as
- unsolicited e-mails unrelated to our domains of interest. These include:
- porn text
- sales pitches about many popular topics:
- pharmaceuticals
- medical treatments, health, age, fitness improvement program
- stock market information (gold or whatever)
- luxury goods (watches, fashion articles)
- contacts supposed to make us richer quickly
- ponzi schemes (= pyramids)
- lottery gains
- offers to transfer money of some african colonel who suddenly died in some accident leaving huge piles of unspent dough somewhere
- phishing (enquiries to send our bank or credit card pin or passwords
because of some supposed security risks)
- advertising for some products
- computer sales, printer toner
- OEM software, "legal" discounted software
- printer offers for printing visit cards, posters, books
- offers for building web sites (well, well, well ...)
- offers to tune, improve or otherwise reference our web sites
- text linking to web site with any of the previous content
We consider as good mail:
- orders or enquiries for trainings, Delphi developments or programming consulting
- contacts from other developers, whether for comments about our articles, help requests, references to similar topics
- news letter subscription (David Intersimone, Joel on Software, Jot)
- on our personal mailbox, family, friends or old school buddies e-mails
- for all the products we ordered (for instance Amazon), feedback (delivery
notices, advertising about similar products). On the other hand, continued advertising flood from a used car sales site where we happened to once tried to sell our old car are not welcome. In the middle, we want our travel
agency's ticket notifications, but not their constant advertising.
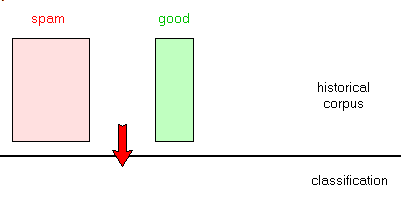
2.2 - To remove or not to remove Reading all the incoming mail becomes painful because you have to decide what
is relevant to your business or activity, and what should be discarded. When the proportion of spam increases, you start to lower your attention, and might throw away some legitimate e-mail.
Automatic spam removal's goal is to automatically eliminate the spam, and let you concentrate on the "good" mail. 100 % spam filtering is not possible: some e-mails are in a gray area (are
aggressive promotion from a company we ordered some product from spam or not) and some e-mails generally considered as spam might not be (an order form a pharmaceutical company).
The best we can do therefore is to eliminate, with some error margin, the spam. The main problem in spam removal, which is severe, is to guarantee never to remove any legitimate mail. We would prefer to read many pharmaceutical junk
mails and perhaps find one day a business request among them, rather than throw them all away.
2.3 - Spam Removal Techniques To remove spam, with the previous stringent constraint of never throwing good
mail away, there are a couple of techniques: - sender (name or URL) blacklists, coupled with "friendly" lists
- sheer size of the e-mail
- filtering out the spam by analyzing the text of the e-mail
The first route requires the availability of an exhaustive, up to date and trustworthy list. This does not seem adequate in our case. Since 2001, when we started our first web sites, URLs did change a lot, and keeping track of this
link between the sender and the quality of the mail is not reliable enough. List of accepted sender e-mails is also only a marginal tool, since we receive all the time mails from people we did not know before.
E-mail size could eliminate some pictures, viruses or random huge texts, but we also sometimes receive photographs from friends, .ZIP attachments or screen captures from our customers. So this is also not an option.
The filtering based on the content of the e-mail therefore looks like the best candidate. We can analyze - the e-mail headers (for instance the "To", the "Subject")
- the text, if any, in standard Notepad format or .HTML format
- the type and content of any attachments
For the content, an empty destination ("To") is a very good spam indicator, but this only constitutes a small percentage of our spams.
To analyze the content, you have to extract the tokens and classify the e-mail based on this token list.
2.4 - Content Filtering Assuming we have the token list for some e-mail, how can we decide whether this
mail should be considered as spam or legitimate ? Our first approach was to build a database of tokens which always indicate spam. No customer ever contacted us with e-mail containing blatent porn tokens
(maybe a friend with some jokes, but if we miss those it would not be catastrophic, and they could also be saved by looking up a "friendly" sender list). So, over time, and with regular updates, we did build a list of all the
"spam words", and the mere presence of one of those tokens allowed us to classify the e-mail as "spam", "maybe spam", "good". This simple one word test allowed us to eliminate 30 % of our e-mail which were spam, but we still had to
look at the "maybe" cases (around 65 %) to make sure we did not miss a "good" mail.
We certainly could have improved this "one bad world" check by using several
words and some boolean expression ("xxx" AND "yyy" OR "uuu" AND NOT "ttt"). In fact we have published a textual
analyzer implementing such a boolean content analysis.
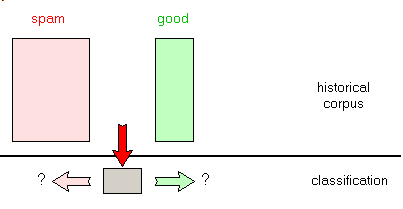
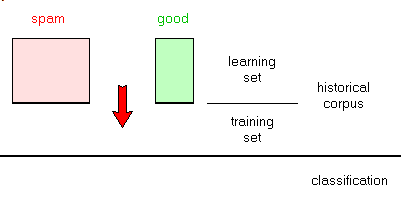
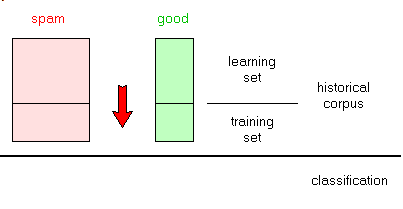
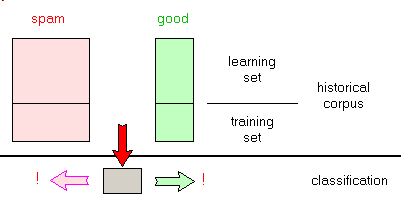
2.5 - Text Classification Therefore we are now facing a text classification machine learning problem, which can be stated as follows:
- given two historical sets of texts, build a piece of software which decides how to classify any of those texts in our categories
- when a new text comes in, determine to which category it belongs
To achieve this - we split the historical sets in two parts, the learning sets and the test
sets:
- the classifier is trained (parametrized) using the learning set:
- we validate (check, adjust) our model using the test set
- finally we use the classifier to filter spam:
To build text classifiers, there are many available techniques: - KNN (k Nearest Neighbours)
- Artificial Neural Networks
- Genetic Programming
- Simmulated Annealing
- Support Vector Machine
- Bayesian Classification
We used all those techniques in forecasting projects, but we will settle down on Bayesian Classification, since this it seems established today that this is
the method of choice to solve Spam filtering, after Paul GRAHAM published his seminal paper.
3 - Paul GRAHAM's Bayes Spam Filter
3.1 - The Algorithm First, build the text classifier, based on your e-mail history :
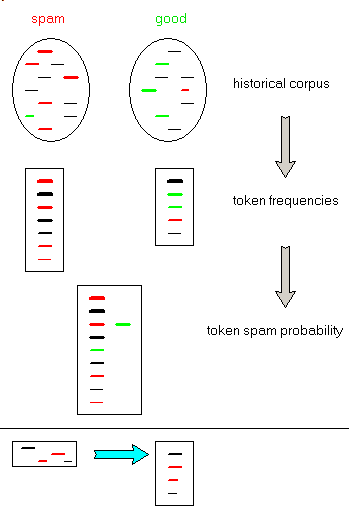
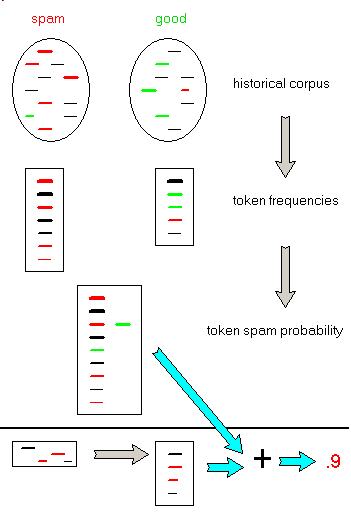
When a new e-mail has to be classified - build the token list of this e-mail:
- using the token spam probability list, compute the spam probability of each
token or this e-mail, and then compute a combined index of being spam
3.2 - Bayes Text Classification
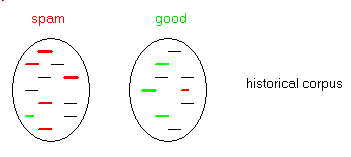
Statistical classification rests on a simple rule of thumb computation: if there are more bad tokens in spam than in ok text, then, if we find more spam tokens in some mail, it should be considered spam. From a more formal point of view
3.3 - GRAHAM's Algorithm This algorithm uses Bayes's formula, with some tweaking in order to reduce the risk of ok-mail elimination. Here are the steps:
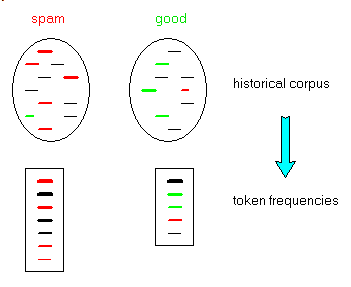
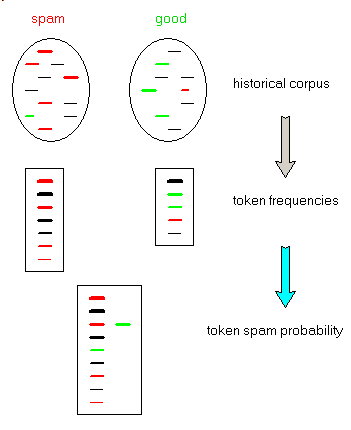
- compute the frequency lists of both spam and ok mails
- build the list of all tokens, and compute a spam probability with the following steps:
- if the occurence of a token in both sets is less than 6, discard this token
- if the token belongs to the ok mails only (not to any spam mail), set its spam probability to 0.1
- if the token belongs to the spam mails only (not to any ok mail), set its probability to 0.9
- in the other cases, set the probability to
ok_factor:= ok_frequency / ok_e_mail_count;
spam_factor:= spam_frequency / spam_e_mail_count;
probability:= spam_factor / (ok_factor + spam_factor); |
- to classify an e-mail
There are additional tweaks
- to bias the computation to avoid missing ok e-mails, the ok frequency is multiplied by 2 when we compute the spam probability
- when a token is only in the spam corpus, we can set increased probabilities
if there are many of those tokens. For instance 0.9 for small frequencies, 0.99 for frequencies greater than 10.
And comments: - the denominator of the probability computations are the spam or e-mail
counts (and NOT the token counts. It is assumed that spam tokens are repetitive, and using e-mail counts tilts the balance in favor of ok e-mails
- the use of a minimum 0.1 and maximum 0.9 avoids that a single token
dominates the composite indicator computation (0 would influence the abc... value, and 1 the (1-a)... value)
4 - The Delphi Implementation of the Bayes classifier 4.1 - The Steps and Structures We will closy follow the algorithm outlined above
- from our e-mail 2 kind of mail history, build the token frequency list, and then the spam probability list
- for each mail extract its token list and compute a composite spam ratio of this e-mail
4.2 - Build a collection of spam and good mail This step is a manual one. We have to place previous mails in two categories, spam and good. It can only be done by visual inspection, since we assume that no tool is
available to do the job for us. In addition, no automatic tool can do it for us, since the kind of spam we receive, and what WE consider as "good" is a matter of self judgement.
Either both collections already exist, or we have to start creating such a list (saving each incoming mail in one or the other collection), and we only start the other steps when we have a substantial corpus of manually categorized
mails. In our case, we started in January 2008 and implemented the spam filter in March.
In our implementation, each e-mail is a .TXT file, and they are saved in two separate folders, SPAM\ and GOOD\. We accumulated around 5,700 spam mails,
and 1,900 ok mails.
4.3 - Tokenizing the spam and good archives This is the easy part: split the text of an e-mail in tokens, and add those tokens to a list, counting the occurences of each one. To do so
- we load the text into a buffer
- we use 2 basic loops
- the first loop skips the characters we consider as separators: spaces, new lines, brackets etc
- the second loop accumulates all characters considered as part of a token,
until we hit a separator or the end of the text
We used 2 kind of scanners (which can be selected by the user): - a first one which scans everything
- a more elaborate parser which takes the structure of e-mail into account.
The first scanner considers - letters, digits, underscores as belonging to tokens
- all other characters as separators
Here is the CLASS definition of the scanner: type c_mail_scanner=
class(c_text_buffer)
m_token_min: Integer;
constructor create_mail_scanner(p_name: String;
p_token_min: Integer);
function f_token: String;
function f_mail_token: String;
end; // c_mail_scanner
|
The raw token extraction is:
function c_mail_scanner.f_token: String;
const k_tokens= ['a'..'z', 'A'..'Z', '0'..'9', '_'];
k_separators= [#0..#255]- k_tokens+ k_digits;
var l_start, l_length: Integer;
begin
repeat
// -- skip separators
while (m_buffer_index< m_buffer_size)
and (m_oa_text_buffer[m_buffer_index] in k_separators) do
inc(m_buffer_index);
l_start:= m_buffer_index;
while (m_buffer_index< m_buffer_size)
and (m_oa_text_buffer[m_buffer_index] in k_tokens) do
inc(m_buffer_index);
l_length:= m_buffer_index- l_start;
if l_length> m_token_min
then begin
SetLength(Result, l_length);
Move(m_oa_text_buffer[l_start], Result[1], l_length);
Break;
end
else Result:= '';
until (m_buffer_index>= m_buffer_size);
end; // add_to_token_list
|
If we want to take into account that the texts are e-mails, we first assume
that it has the following structure: - POP3 headers (TO, FROM, SUBJECT, DATE etc)
- a blank line
- a combination of
- ASCII text
- .HTML text
- uuEncoded text
- possibly with multipart Mime structure, with some of the following Content-Types
- text/plain
- text/html
- image
- application
The textual parts may contain Mime encoding (=HH for coding non-english
characters), and line breaks (= followed by Return LineFeed, to keep the lines shorter than 72 characters)
The e-mail scanner therefore accepts the "=" character, and
- for =HH (hex digits: 0..9, A..F), we simply include them in the token (assuming that when a token contains some =HH, this will be the case for all e-mails)
- for =RL, we remove them if they occur in the middle of some token
The f_mail_token FUNCTION implements those ideas, and you can find it in the downloadable .ZIP source code.
4.4 - Building the Token frequency list 4.4.1 - Requirements
The requirements for the token frequency list are the following: - store (string, integer) values in memory
- for each new token, lookup for the list to check whether a string already
exists, and increment the frequencies if this is the case. This involves searching the list for an entry
- eventually after the analysis, persist this structure on disc to be able to
avoid reanalyzing the training set each time we want to filter new mail
A tStringList fits the bill. A sorted tStringList will improve the search,
but we will also incur the cost of sorting. In fact any hash structure (find an entry, given the key) would be more appropriate. Delphi does not include any convenient hash container, so we created our own.
4.4.2 - The Delphi String Hash Table
Here is the CLASS definition:
t_hash_data= record
m_hash_string: string;
m_hash_frequency: integer;
// -- for the token spam probability list
m_hash_probability: Double;
end;
t_pt_hash_data= ^t_hash_data;
c_hash_bucket=
class(c_basic_object)
_m_c_hash_data_list: TList;
constructor create_hash_bucket(p_name: String);
function f_hash_data_count: Integer;
function f_pt_hash_data(p_hash_index: Integer): t_pt_hash_data;
function f_pt_add_hash_data(const pk_hash_string: String; p_integer: Integer): t_pt_hash_data;
function f_pt_search_hash_data(const pk_hash_string: string): t_pt_hash_data;
destructor Destroy; override;
end; // c_hash_bucket
c_hash_table=
class(c_basic_object)
_m_hash_bucket_array: array of c_hash_bucket;
_m_bucket_count: Integer;
constructor create_hash_table(p_name: String;
p_requested_bucket_count: integer= 1023);
procedure _initialize_hash(p_bucket_count, p_hash_type: integer);
function f_bucket_count: Integer;
function f_c_bucket(p_bucket_index: Integer): c_hash_bucket;
function f_string_hash_value(const pk_hash_string: string): integer;
function f_pt_add_hash_data(const pk_hash_string: String;
p_integer: Integer): t_pt_hash_data;
function f_pt_add_hash_probability_data(const pk_hash_string: String;
p_integer: Integer; p_probability: Double): t_pt_hash_data;
function f_pt_search_hash_data(const pk_search_string: string):
t_pt_hash_data;
function f_used_bucket_count: Integer;
function f_hash_data_count: integer;
procedure display_hash_table;
destructor Destroy; override;
end; // c_hash_table
|
and - each hash cell contains the string and the frequency (plus the probability
which is used for the spam probability list)
- those cells are stored in buckets, where hash cells are added when no entry exists for this string
- the hash table
- builds a predefined number of buckets
- uses f_string_hash_value to compute the hash bucket. Any string hash function will do (CRC, ELF or whatever)
- calls f_pt_add_hash_data to create a new entry with frequency 1 or increment the frequency by 1
- uses f_pt_search_hash_data return the data cell or NIL if no such cell exists. The FUNCTION is used to check whether an entry already exists or to retrieve a cell when we later use the hash table
To abstract the browsing of this hash table, we added an iterator, with a semantic similar to the .Net iterators:
c_hash_iterator=
Class(c_basic_object)
_m_c_hash_table_ref: c_hash_table;
_m_bucket_index: Integer;
_m_hash_data_index: Integer;
constructor create_hash_iterator(p_name: String;
p_c_hash_table_ref: c_hash_table);
function f_move_next: Boolean;
function f_pt_current_hash_data: t_pt_hash_data;
end; // c_hash_iterator
|
So this is just a minimal hash table, and in fact it accelerated the
computation compared to our first tStringList trial.
4.4.3 - Building token frequency lists Building the frequency list of some text is a simple: - create the token frequency list
- create a scanner and load the text
- while there are tokens in the text, add those tokens to the list, either creating a new token with frequency 1 or incrementing the frequency for some already entered token.
This parsing is done in three cases - for analyzing each spam or ok mail. In this case
- for spam, the list is created first, and we iterate thru the corpus spam
mails, to scan and add the mail tokens to the spam token frequency list
- same technique for the ok mails
- for analyzing each new mail. A new list is then created and filled only for this mail
The code for this computation is the following:
with my_c_mail_scanner do
begin
while m_buffer_index< m_buffer_size do
begin
l_token:= LowerCase(f_token);
if l_token= ''
then // -- end of the text
else my_c_token_frequency_list.f_pt_add_hash_data(l_token, 1)
end; // while m_buffer_index
end; // with my_c_mail_scanner
|
4.5 - The token spam probability list 4.5.1 - The algorithm Once we have our two token / frequency lists, we combine them into a token spam probability list.
Each entry in this list is spam only, good only or both spam and good. One way to build this list is the following: - start with one list, say good
- for each token in this first list
- get its frequency
- look up the other list and get its frequency
- then combine the frequencies to compute the probability
- take the other list, say spam
- for each token
- if this token does not belong to the first list (ie has not been handled), then add an entry with a 1.0 probability
Once this list is created, when a new mail has to be classified, we will have
to lookup this list to find the spam probability of each new mail token.
4.5.2 - The spam probability list requirements Any searchable (String, Double) structure will do. However since we will have
to lookup this list (both for guaranteing uniqueness at building time, and for extracting the spam probability for new mails later), a hash structure is the most appropriate.
We could have build a specific (String, Double) hash table, but we chose to recycle the previous string hash table, adding a Double field just for this spam probability list.
4.6 - The c_bayes_spam_filter CLASS 4.6.1 - The CLASS definition c_bayes_spam_filter=
class(c_basic_object)
m_e_mail_parsing: Boolean;
m_c_ok_hash_token_frequency_list,
m_c_spam_hash_token_frequency_list: c_hash_table;
m_c_spam_token_probability_list: c_hash_table;
Constructor create_bayes_spam_filter(p_name: String);
procedure _add_raw_tokens(p_c_mail_scanner: c_mail_scanner;
p_c_test_hash_token_frequency_list: c_hash_table;
p_is_spam: Boolean);
procedure _add_e_mail_file_tokens(p_c_mail_scanner: c_mail_scanner;
p_c_test_hash_token_frequency_list: c_hash_table;
p_is_spam: Boolean);
procedure add_file_tokens(p_full_file_name: string;
p_is_spam: Boolean);
procedure compute_spam_probabilities;
function f_test_mail(p_full_file_name: String;
p_c_result_list: tStrings): Double;
Destructor Destroy; Override;
end; // c_bayes_spam_filter
|
and:
- m_e_mail_scanning allows to select either raw scanning (all text) or mail scanning (only content, and after some MIME decoding)
- m_c_ok_hash_token_frequency_list and m_c_spam_hash_token_frequency_list
will contain the token frequencies from our two training sets
- m_c_spam_token_probability_list is the training token spam probability list
- _add_raw_tokens and _add_e_mail_file_tokens are helper function for
building raw or e-mail frequency lists
- add_file_tokens is called to add the frequencies of each mail from the training sets:
procedure c_bayes_spam_filter.add_file_tokens(p_full_file_name: string;
p_is_spam: Boolean);
begin
with c_mail_scanner.create_mail_scanner('', m_token_length_min) do
begin
f_load_from_file(p_full_file_name);
if m_e_mail_scanning
then _add_e_mail_file_tokens(f_c_self, Nil, p_is_spam)
else _add_raw_tokens(f_c_self, Nil, p_is_spam);
Free;
end; // with c_mail_scanner
end; // add_file_tokens
| - compute_spam_probabilities does just what the name indicates:
procedure c_bayes_spam_filter.compute_spam_probabilities;
procedure compute_token_probability(p_token: String;
p_ok_frequency, p_spam_frequency: Integer);
var l_ok_frequency, l_spam_frequency: Integer;
l_ok_factor, l_spam_factor, l_probability: Double;
begin
l_ok_frequency:= p_ok_frequency* m_ok_token_weight;
l_spam_frequency:= p_spam_frequency;
// -- only compute if has found significant occurences in the
// -- spam+ ok corpus
if l_ok_frequency + l_spam_frequency >= m_min_token_count
then begin
if l_spam_frequency= 0
then l_probability:= m_score_min
else
if l_ok_frequency= 0
then begin
// -- special case for Spam-only tokens.
// -- - 0.9998 for tokens only found in spam,
// -- - 0.9999 if found more than 10 times
if l_spam_frequency > m_certain_spam_count
then l_probability:= m_certain_spam_score
else l_probability:= m_likely_spam_score;
end
else begin
// -- in both spam and ok sets
l_ok_factor:= l_ok_frequency / m_ok_e_mail_count;
l_spam_factor:= l_spam_frequency / m_spam_e_mail_count;
l_probability:= l_spam_factor / (l_ok_factor + l_spam_factor);
end;
// -- now add the probability entry
// -- include the total occurence, only for analysis
m_c_spam_token_probability_list.f_pt_add_hash_probability_data(p_token,
l_ok_frequency + l_spam_frequency, l_probability);
end; // occured more than 5 time
end; // compute_token_probability
var l_ok_token, l_spam_token: String;
l_pt_spam_hash_data: t_pt_hash_data;
l_ok_frequency, l_spam_frequency: Integer;
begin // compute_spam_probabilities
m_c_spam_token_probability_list.Free;
m_c_spam_token_probability_list:= c_hash_table.create_hash_table('');
with c_hash_iterator.create_hash_iterator('',
m_c_ok_hash_token_frequency_list) do
begin
while f_move_next do
with f_pt_current_hash_data^ do
begin
l_ok_frequency:= m_hash_frequency;
l_ok_token:= m_hash_string;
// -- find out if this token also has a spam value
l_pt_spam_hash_data:=
m_c_spam_hash_token_frequency_list.f_pt_search_hash_data(l_ok_token);
if l_pt_spam_hash_data<> nil
then l_spam_frequency:= l_pt_spam_hash_data.m_hash_frequency
else l_spam_frequency:= 0;
compute_token_probability(l_ok_token, l_ok_frequency, l_spam_frequency);
end; // while f_move_next
Free;
end; // with c_hash_iterator.create_hash_iterator
with c_hash_iterator.create_hash_iterator('',
m_c_spam_hash_token_frequency_list) do
begin
while f_move_next do
with f_pt_current_hash_data^ do
begin
// -- eliminate what was added while browsing the "ok" list
l_spam_token:= m_hash_string;
if m_c_ok_hash_token_frequency_list.f_pt_search_hash_data(l_spam_token)= Nil
then begin
l_spam_frequency:= m_hash_frequency;
compute_token_probability(l_spam_token, 0, l_spam_frequency);
end;
end; // while f_move_next
Free;
end; // with c_hash_iterator.create_hash_iterator
end; // compute_spam_probabilities
| - f_test_mail is used to compute the composite spam coefficient of any mail.
Before presenting the code, we will show our "most interesting" structure
4.6.2 - Computing the 15 most interesting values To rank a new mail, we compute its 15 most interesting values (meaning the
tokens with the highest or lowest spam probability, possibly discarding the equally probable tokens). This involves extracting the top 15 values in a list of Double.
We first used a sorted tStringList, converting the Doubles into formatted strings. Feeling that this conversion was not efficient, we then used a binary tree, sorted on the double value. Because the tree keeps all the values, we
changed again to use an array limited to 15 values, wich is sorted to easily keep track of the lowest value. This is not the most interesting part of the code (pun intended), but here it is:
procedure c_most_interesting_list.add_most_interesting_decreasing(
p_how_far_away_from_05, p_probability: Double; p_token: String);
var l_insert_index: Integer;
l_move_index: Integer;
begin
if m_count= 0
then begin
// -- empty: insert at the first position
l_insert_index:= 0;
// -- prepare next
Inc(m_count);
end
else
// -- only insert if
// -- - either not full
// -- - or the probability is greater then our smallest probability
if (p_how_far_away_from_05>
m_most_interesting_array[m_count- 1].m_how_far_away_from_05)
or (m_count< m_count_max)
then begin
// -- find the last item lower than our probability
l_insert_index:= 0;
while (l_insert_index< m_count)
and (m_most_interesting_array[l_insert_index].m_how_far_away_from_05>=
p_how_far_away_from_05) do
Inc(l_insert_index);
if m_count< m_count_max
then Inc(m_count);
end
else // -- too small: no insertion
l_insert_index:= -1;
if l_insert_index>= 0
then begin
if l_insert_index< m_count- 1
then
for l_move_index:= m_count- 1 downto l_insert_index+ 1 do
m_most_interesting_array[l_move_index]:=
m_most_interesting_array[l_move_index- 1];
// -- now insert
m_most_interesting_array[l_insert_index].m_how_far_away_from_05:=
p_how_far_away_from_05;
m_most_interesting_array[l_insert_index].m_probability:=
p_probability;
m_most_interesting_array[l_insert_index].m_token:=
p_token;
end;
end; // add_most_interesting_decreasing
|
4.6.3 - Testing a new mail
Let's go back to our c_bayes_spam_filter to show how we rank a new e-mail. We must - build the frequency list for this text
- compute the array of the 15 most interesting values
- merge those values into a composite index
Here is the code:
function c_bayes_spam_filter.f_test_mail(p_full_file_name: String;
p_c_result_list: tStrings): Double;
var l_c_test_mail_token_frequency_list: c_hash_table;
procedure build_mail_token_list;
begin
with c_mail_scanner.create_mail_scanner('', m_token_length_min) do
begin
f_load_from_file(p_full_file_name);
if m_e_mail_scanning
then _add_e_mail_file_tokens(f_c_self,
l_c_test_mail_token_frequency_list, True)
else _add_raw_tokens(f_c_self,
l_c_test_mail_token_frequency_list, True);
Free;
end; // with c_mail_scanner
end; // build_mail_token_list
var l_c_email_most_interesting_list: c_most_interesting_list;
procedure compute_mail_token_probabilities;
var l_mail_token: String;
l_pt_mail_hash_data: t_pt_hash_data;
l_spam_probability: Double;
l_how_far_away_from_05: Double;
begin
l_c_email_most_interesting_list:=
c_most_interesting_list.create_most_interesting_list('',
m_interesting_word_count);
with c_hash_iterator.create_hash_iterator('',
l_c_test_mail_token_frequency_list) do
begin
while f_move_next do
with f_pt_current_hash_data^ do
begin
l_mail_token:= m_hash_string;
l_pt_mail_hash_data:=
m_c_spam_token_probability_list.f_pt_search_hash_data(l_mail_token);
if l_pt_mail_hash_data<> Nil
then l_spam_probability:= l_pt_mail_hash_data^.m_hash_probability
else l_spam_probability:= m_e_mail_unknown_token_probability;
l_how_far_away_from_05:= Abs(0.5- l_spam_probability);
l_c_email_most_interesting_list.add_most_interesting_decreasing(
l_how_far_away_from_05, l_spam_probability, l_mail_token);
end; // while f_move_next
Free;
end; // with c_hash_iterator.create_hash_iterator
end; // compute_mail_token_probabilities
procedure compute_composite_with_most_spams;
var // -- abc..n
l_mutliplied: Double;
// -- (1 - a)(1 - b)(1 - c)..(1-n)
l_complement_mutilplied: Double;
l_best_index: Integer;
l_probability: Double;
l_ratio: Double;
begin
l_mutliplied:= 1;
l_complement_mutilplied:= 1;
p_c_result_list.Clear;
with l_c_email_most_interesting_list do
for l_best_index:= 0 to m_count- 1 do
with m_most_interesting_array[l_best_index] do
begin
l_probability:= m_probability;
l_mutliplied:= l_mutliplied * l_probability;
l_complement_mutilplied:= l_complement_mutilplied
* (1 - l_probability);
l_ratio:= l_mutliplied / (l_mutliplied + l_complement_mutilplied);
p_c_result_list.Add(Format('proba %0.7f away %0.7f => ratio %1.7f ',
[l_probability, m_how_far_away_from_05, l_ratio])+ m_token);
end; // with l_c_email_most_interesting_list
Result:= l_mutliplied / (l_mutliplied + l_complement_mutilplied);
end; // compute_composite_with_most_spams
begin // f_test_mail
l_c_test_mail_token_frequency_list:= c_hash_table.create_hash_table('');
build_mail_token_list;
compute_mail_token_probabilities;
compute_composite_with_most_spams;
l_c_test_mail_token_frequency_list.Free;
end; // f_test_mail
|
4.7 - The main project The rest of the project is purely administrative:
- we use our usual DirectoryListbox / tFileListBox to select the files. Spam training mails are located in a SPAM\ folder, ok training mails in OK\, spam testing mails in TEST_SPAM\ and ok testing mails in TEST_OK\
- the "compute" button analyzes the files in the training folders. A proportion of those files is not included, but copied instead in the test folders
- the "compute_probabilities_" computes the token spam probability list. The
result may be examined in a tMemo
- the "test_ok_mail_" and "test_spam_mail_" buttons analyze the mails kept for testing. The result is displayed in a tListBox on the right, and clicking on the listbox displays
- the most interesting tokens with their probabilities
- the raw mail, the content text and .html, the full token list
Here is a snapshot of the execution after the training:
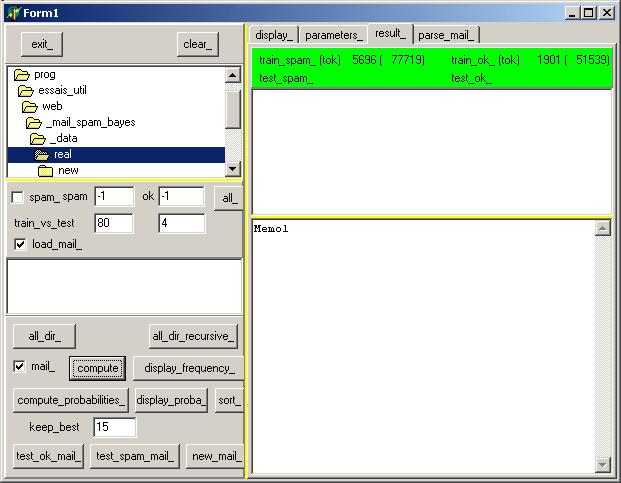
After clicking "test_spam_mail" this becomes: 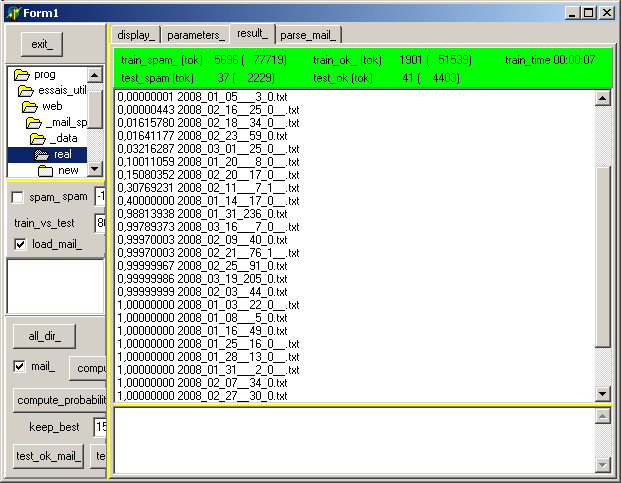
where the first column is the composite index, followed by the e-mail file name.
We can check the tokens of an e-mail to get some explanation why some mail is considered as spam, by clicking on this item in the tListBox :
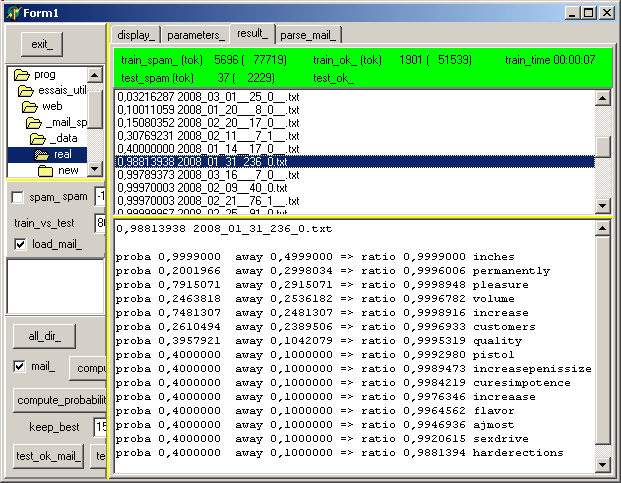 Well, this sure explains it ! More seriously, notice that - the list is presented in "interesting order", which means the most away from
the .5 value come first. The spam probabilities are also displayed.
- "inches" is the highest on the spam probability list (nobody ever wrote us to order "inches", or comment about "inches". On the other hand ... )
- some are in between : "increase" (could be the increase of an order quote) or "pleasure" (like "my pleasure" maybe)
- "sexdrive" and other dubiouos tokens are in the middle and were assigned the
modest default .40 value, because they were neither in the bad nor in the ok training sets
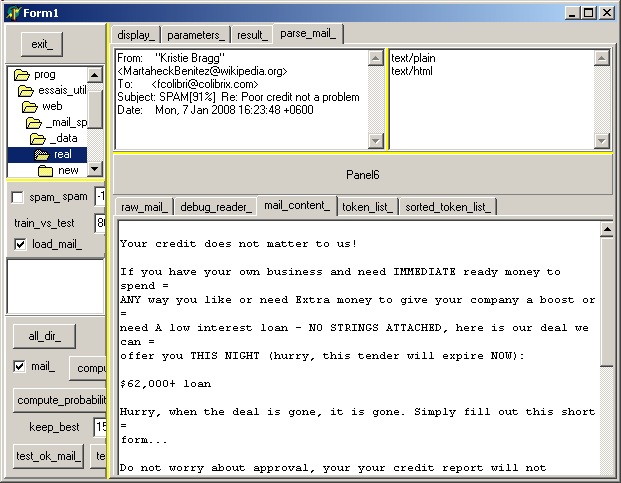
And if we select the "parse_mail_" (of a more innocent mail), we can examine see: - the raw e-mail content
- the ASCII and .HTML parts (no headers, no binary attachment)
- the token list (sorted by frequency or alphabetically)
4.8 - Mini HowTo On the following figure: 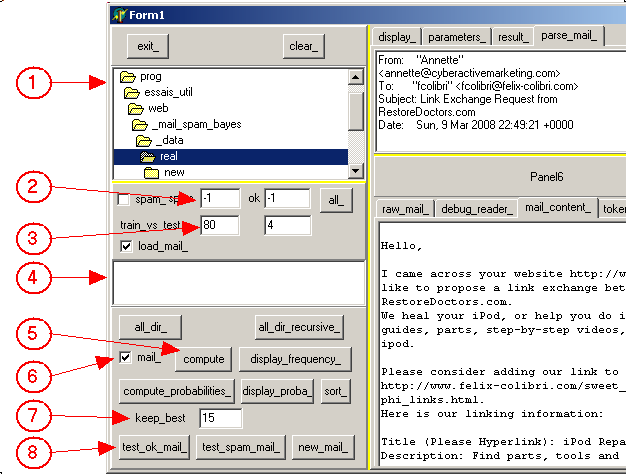
and:
- (1) is the tDirectoryListbox containing the sub folders with all our e-mail files
- (2 ) allows to limit the number of files to include in the training phase, -1 for "all files"
- (3) is the training / test ratio. "80" means 1 out of 80 files will be kept for testing
- (4) is the tFileListBox where we can display the files of some folder. Clicking on one of them will analyze it (.HTML extraction and token
frequencies) and display in the right "parse_mail_" tab
- (5) starts the training. The result (file count, token count, time) is displayed in the "result_" tab on the right
- (6) allows to toggle between raw scanning and .HTML scanning
- "compute_probability_" will create the token spam probability list
- (7) is used to specify how many token probabilities are kept for the final computation
- (8) will test all the ok mail (spam mail, any other mail). The list or the
results appears in "result_" on the right, with a tListbox. Clicking one of the items will display its token list with their probabilities
This manual is quite short, but perhaps "Annette" at "RestoreDoctors.com" will
be able to help you ? Notice that we have nothing against cross links request, but the other site must have SOME relation with Delphi
4.9 - The Results
Here are our first results (after 3 days of developing the project and writing the article): - our training database consists of 5,700 spam mails and 1,900 ok mails, with 75,000 and 46,000 token
- training took 1 minute on a freshly booted PC (2.8 Meg clock, 512 Meg memory), and 10 seconds for the next trials (due to the cache)
- on 163 ok test mails, 1 was at 0.006 (a two line congratulation mail), the rest at 0 (1e-7)
- on 152 spam test mails
- 105 were at more than 0.96
- 15 between 0.96 and 0.10
- 31 near 0
The conclusion is that on 315 mails: - we had no ok mail considered as spam
- we still need to read 46 mails only to throw them out as spam
This is far better than our primitive "1 spam word filter", but nearly not as performing as the results claimed by GRAHAM. The good news is there is still
room for improvement !
As usual, the nice thing of having a Delphi project (versus a shrink wrapped spam filter) is that it allows us to accumulate all kinds of statistics in
order optimize spam elimination, and in addition we can include it in our mail POP3 downloader and mail viewer suite.
5 - Improvements, Implementation and Comments 5.1 - Downloading Mail
To download mail from our mail server, we use Windows Sockets. We only used Outlook at the beginning of Windows because we did not know how to do otherwise. But switched to a howgrown POP3 project as soon as we could, since
we never were sure of what was or not unzipped or executed by Outlook. With pure sockets, ASCII files loaded in a tMemo can NEVER start any kind of script. And if the mail contains some attachment, WE decide to decode it or not.
This e-mail files approach nicely fit with the filter learning, since we had kept enough spam (fearing to have missed some ok mail) to train the Bayes filter. Nevertheless, many users do not use this two step approach (download with one
software and read the files with another). So it would be nice to tie the filter to Outlook or any other popular downloader / reader. This has been done with some spam filtering projects like SpamAssassin. We will not investigate
this further, unless some customer asks us to do it. Notice that coupling the Bayesian filter with Indy (or ICS, Synapse or whatever) POP3 mail clients should not be very difficult.
5.1.1 - The Options
We parametrized (like GRAHAM showed us) the spam filter with many values: minimal token frequency, bonus factor for the tokens of ok mails. Our .ZIP presents the current values, but they can, of course be changed (in the
"parameters" tab) if you feel they would improve the result. Among the possibilities - increase the minimum token length. Because of uuEncoded text, our one word filter did not check for tokens smaller than 6 characters. The "sex" or
"xanax" combination can be present in any uuEncoded text (this is a bitter memory since we once missed an order because of this).
With the .HTML scanner presented here, we would not scan the uuEncoded text,
and could well include 3 characters spam ("sex"), 4 character ones ("loan", "cock") or 5 character ones ("stock", "watch", "gucci", "cialis") - we could also build a case for splitting, or even eliminating from the
analysis, too long tokens. In our case, they occured when we scanned uuEncoded text which was not included in a MIME multipart. Decoding uuEncoded text would remove this option
- for our "1 token filter", and for the first trials of the Bayesian filter, we used to scan the full text. We then realized that most mails are rather short. In our case, when we send mail, we use only ASCII text (no .HTML
monkeing), and 30 or 40 lines max. The average in our training set is around 3100 bytes. Spam on the other hand is rather bulky. Our training spam set's mean size is near 19,300 bytes. This is not a surprise, since spam often
contains attached images, binary viruses or whatever MIME encoded stuff.
To reduce the development time, we first limited the analyzed text to 4 K. It turned out that this is even more than our .HTML parser analyzes (he only
looks at "text/plain" and "text/html", and quits at the first occurence of an "image" or other multipart. But you might change this 4 K scanner limit.
As with any machine learning project, the learning algorithm is usually well explained and can be quickly implemented, but the tuning of the system is still an important part of the work.
5.1.2 - Which tokens should we use
We selected to extract near-pascal tokens (letters plus some underscore, digit, minus). We also decided to only analyze lowercase tokens. Among the other possibilities, we can mention
- add "!" and "?" when they are present at the end of a token ("free!!!"). This catches many otherwise innocuous tokens, but multiplies the tokens ("free", "free!", "free!!" etc)
- keep the casing. This also increases the token count (which is like decreasing the training population). Many phishing from Africa are uppercase only, and this would be a good cue.
- one word filtering was fought back by spammers by including look-alike characters ("v|agra" or "c0ck") doubling some vowels ("viiiiagra") or inserting consonants ("Buyz nViagra"). Our one word filters did try to
remove those, but of course this slowed the filtering down. On the other hand modified or mangled tokens ("st0ck") would be much more incrimating than usual ones ("stock")
- we added hex-digits since the occur in .HTML colors, which are sometimes
used by spammers in the desparate attempt to draw your attention
Also important, we could add - decode uuEncoded text (for this project, we scanned the whole thing "as is",
which is meaningless. We somehow remember that some mail writer only sends uuEncoded text, but this is not a significant proportion of our e-mails.
- perform some "link following". Many porn spams simply invite you to visit
some site, with some surprises if you go there. The actual e-mail is short, and therefore quite difficult to classify. Link following would require to add some .HTML downloader or .HTML
spider. We presented those kind of tools on this site, and it would be easy to add them to the filter
- perform some special handling of "very short mails" (10 or 20 tokens) which
spammer send you just to waste your time. Legitimate mail usually is longer (saying "Hello", "Regards", signiture already takes around 10 tokens)
5.1.3 - The Containers
We are quite happy with the hash tables. Using tStringLists for analyzing 9,000 files was hopeless. We certainly could improve our hash table: - we kept a default 1024 bucket structure, but this could be tailored to the training set
- we chose the first available hash function. Some experiments could demonstrate that other hash function would better spread the tokens among the buckets
- within buckets, we used tLists, but maybe some more efficient structure
could improve speed
- we used the same CLASS for both frequency counts and spam probability. We could easily create 2 separate structures, or implement an abstract hash
table CLASS with two descendents. This has been done, for instance by Peter BELOW, with source code in Code Central. We did not check, but believe that the hash data must then be in a CLASS, and this would necessitate
allocation of 121,000 objects for the training, whereas we only had to allocate as many pointed RECORDS.
With Delphi 2008, we might even use Generics In a
3 day development, you have to take some shortcuts, and we kept our single structure. The 1 minute training (10 seconds for the next ones) just fitted the bill, and this is only an optimizing concern which is not the main goal
when developing such a new project.
The "most interesting" 15 token list was first implemented as a binary tree. This is the structure we used again and again in Pascal. It has somehow
vanished since Delphi offered the sorted tStringList. In the filtering project we implemented a fixed size array with some kind of push down insert sort. In retrospect, our e-mail contain on average about 12 token (
(75,000+46,000)/(5,700+1,900) ) so it looks like a lot of work for a small gain. And the binary tree avoids any index computing, which is usually a huge time gain. Therefore we might reintroduce our beloved binary tree in the next version.
The goal of the training phase is to compute the token spam probability list. If the training set is huge (or if more elaborate scanners which take more time are used), it becomes necessary to separate the training / testing from the
production phase. This then requires the persistence of the token spam probability list on disc. Hash tables are easy to save into a file (or a database), since reading them
back will produce the same structure. There is no degenerescence risk as with binary trees. We could adopt all kind of intermediate steps: persist the token frequency lists, and recompute the token spam probability list from those, or use a
sliding window approach for the learning (persist each monthly result on disc, compute only the current month, and build the new monthly values from the current month values plus some previous month's values)
In C#, can use some predefined CLASSes, like the Dictionary, hash tables. We also have scanners and regular expression parsers. We did not try to code the filter in C#, and we do not expect any speed improvements from coding in C#, to
say the least. So, coding might be quicker (assuming we have climbed the learning curve to understand all those wondeful CLASSes), but the training and production speed might not improve.
5.2 - Why Bayesian Filtering Works
Why does Bayesian filtering works compared to technique like blacklist, of filtering based on list of spam token for instance ? The answer is easy: adaptation to what YOU consider as spam or ok mails.
Whether unsolicited Amazon advertising or request to review Delphi products is spam or not is your choice. And the Bayesian learning will adapt to it.
Will it always work ? Well as long as the spam and ok training sets can be
analyzed by Bayesian statistical techniques. For the present time, we classify the spammers in several categories: - the ones that try to sell you something. The corpus of there spam by
necessity contains the tokens in the domain of what they are trying to sell you, and the statistical analysis will quickly eliminate those.
- the ones which simply try to waste your time. The same kind of guy which
scraches your car, tags your home, or spend time writing viruses.
Those are the potentially dangerous one. They could one day adapt the spam to your domain of interest. We started to receive some e-mail which
contained a shuffling of programming words. The spammers can find our e-mail on our web pages. Then could therefore analyze this page's content, and build some text based on similar words (Delphi, CLASSes, Sockets etc).
However, even if they did adopt such a strategy, they will not be able to closely target the content to the same category as our "good" e-mails, as derived from our history list, since they have never seen our ok mail list.
What they can analyze is one or two of our web pages, what then cannot analyze is our "good" e-mail corpus. The domain of all our web pages is not the same as the domain of the e-mails we want to read.
- the last category includes gray mails : the one we accept or reject based on context (we ordered a plane ticket and wait for the acknowlegement versus we receive advertising for some trip. Or worse, we throw away tax reduction
schemes, but when the tax filing time comes, we might accept the same mail in the hope to learn some new tricks). Removing those spam would require enought data to separate the spam from the good, and this will seldom be the case.
5.3 - Anti Spam bottom line An improved solution will by necessity include several techniques. We plan to implement the following features - keep blacklists based on FROM. Some companies keep sending us time and
again, the same commercial offer (for printer toner, or presenting resumes of job candidates, for instance)
- since we now have a "reasonably efficient" parser, implement some boolean
logic filters based on some blatent spam tokens ("xxx OR yyy").
- the remainder will pass thru the Bayesian filter
5.4 - Other use of the Bayesian filter
And we can also mention that the Bayesian filtering technique presented here can be used for other text classification. For instance Web page analysis before downloading. If we want to classify in more than 2 categories, we would have to generalize
the algorithm. And we have to remove the strong "spam filtering" bias of the present tool.
6 - Download the Sources of the Spam Filter Here are the source code files: The .ZIP file(s) contain: - the main program (.DPR, .DOF, .RES), the main form (.PAS, .DFM), and any
other auxiliary form
- any .TXT for parameters, samples, test data
- all units (.PAS) for units
Those .ZIP - are self-contained: you will not need any other product (unless expressly mentioned).
- for Delphi 6 projects, can be used from any folder (the pathes are RELATIVE)
- will not modify your PC in any way beyond the path where you placed the .ZIP (no registry changes, no path creation etc).
To use the .ZIP:
- create or select any folder of your choice
- unzip the downloaded file
- using Delphi, compile and execute
To remove the .ZIP simply delete the folder.
The Pascal code uses the Alsacian notation, which prefixes identifier by program area: K_onstant, T_ype, G_lobal, L_ocal, P_arametre, F_unction, C_lass etc. This notation is presented in the Alsacian Notation paper.
As usual:
- please tell us at fcolibri@felix-colibri.com if you found some errors, mistakes, bugs, broken links or had some problem downloading the file. Resulting corrections will
be helpful for other readers
- we welcome any comment, criticism, enhancement, other sources or reference suggestion. Just send an e-mail to fcolibri@felix-colibri.com.
- or more simply, enter your (anonymous or with your e-mail if you want an answer) comments below and clic the "send" button
- and if you liked this article, talk about this site to your fellow developpers, add a link to your links page ou mention our articles in your blog or newsgroup posts when relevant. That's the way we operate:
the more traffic and Google references we get, the more articles we will write.
7 - References For the Bayesian spam filtering algorithm, here are a couple of links
There are many open source implementations of spam filtering, some of them implementing more or less GRAHAM's ideas, and usually adding additional rules.
One of the most well known is
Our hosting company contacted us early march to tell us that he change his mail server. He was receiving over 300.000 spams a day (some of his customers do business with Russia). He replaced his previous server which used "site spam
filtering" to a new new tool implementing "per customer" spam filtering. Being curious, we asked him about the technique, and he mentionned "Bayesian Filtering". We knew about the technique but had not made the link to spam
filtering. And this encouraged us to build this project. In addition, let me mention that he hosts our web sites since 2001. We chose him because: - he accepts binary CGIs. In addition to the usage of Interbase or Firebird
if your site requires some database
- I can download the IIS log of all my sites every morning and know which articles interest my readers
- in 7 years, we spotted that 2 or 3 times, there were holes in the hourly
download profile. We called him, and we had him on the phone within 5 minutes. He is a Delphi guy, so the discussion is very easy, and those rare problems were solved within the hour
I do not believe many providers can beat this kind of offer. You may look at his page at DelphiCenter.net
Here are the papers related to this filter on this site:
- the Web Spider or the Web Downloader which
can be included in an anti spam tool to perform link following
- the Coliget Text Search Engine : a project implementing textual search
- the Delphi Generics Tutorial : an introduction to Generics (parameterized types) which
will be included in Delphi 2008 and can be used to implement hash table hierarchies
- we also published many articles about socket programming (see the top left menu), in case you want to implement you own POP3 downloader.
8 - The author Felix John COLIBRI works at the Pascal Institute. Starting with Pascal in 1979, he then became involved with Object
Oriented Programming, Delphi, Sql, Tcp/Ip, Html, UML. Currently, he is mainly active in the area of custom software
development (new projects, maintenance, audits, BDE migration, Delphi Xe_n migrations, refactoring), Delphi Consulting and Delph training. His web site features tutorials, technical papers about programming with full downloadable source
code, and the description and calendar of forthcoming Delphi, FireBird, Tcp/IP, Web Services, OOP / UML, Design Patterns, Unit Testing training sessions.
|