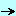|
Web Downloader - Felix John COLIBRI. |
- abstract : the Downloader allows the download of web pages with their associated files (image).
- key words : Off-line reader - HTTP - HTML - anchor - IMG tag - client socket - URL parser - URL ebnf - HTML anchor parser
- software used : Windows XP, Delphi 6
- hardware used : Pentium 1.400Mhz, 256 M memory, 140 G hard disc
- scope : Delphi 1 to 8 for Windows, Kylix
- level : Delphi developer
- plan :
1 - Introduction Every now and then, Internet Explorer causes trouble when I try to save some
page read from the Web. The page was well received and displayed, but "save as" either takes hours or simply refuses to save the page, and this usually after a couple of minutes and a "99 % saved" message.
I have no cue why this happens. Sure, I use maximum security (ActiveX are not tolerated), or maybe there are some other options that were not correctly set. Still, it is very frustrating to know that the packets have been received, that
they are even sitting somewhere in a cache, and refuse to be transfered to another disc location. So the purpose of this project is to download a page (and its associated image
or other binary files) and save it in a file for later off-line reading or display. There could also be some other benefits: - change some page colors (some white on black pages are not very easy to read)
- download a page and read it from disc after disconnecting from the Web, to avoid any advertising pop-up (some contrieved pop-up blocker, but it works)
- some page allow to call another HTML page which is presented in another
window, but this second window has no menu. This page then can be neither saved nor printed. If we download the page using HTTP calls, and save it locally, we can do whatever we like with it.
2 - Downloader Principle 2.1 - Single page download Downloading a single file is easy enough. Our HTTP papers
(simple_web_server, simple_cgi_web_server ) showed how to do this
- lets assume that the URL of the page is http://www.borland.com/index.html
- we use WinSock to do a lookup, which tells us that the ip address is 80.15.236.173
- we then use a WinSocket to connect to this Server
- once the connection is established, we sent the following GET request:
GET /index.html HTTP/1.0
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
Host: www.borland.com
|
- our socket waits and reads the result sent by the Server
There is just a couple of HTTP header settings which could be problematic: - some servers require a "Host" header line
- we can add zip encoding, but have to include the zip decoding upon reception (which we did not include)
- similarily, we could request "Request-live" to avoid creating new sockets for each request. This was also skipped.
In any case, if a page can be downloaded by Internet Explorer but cannot be fetched using our downloader, we simply analyze IE's packets using our
tcp_ip_sniffer , and add the mandatory lines to our downloader's GET.
2.2 - Which requests should be sent ? The basic request parameter is the page or file name:
Usual requests are for pages are whose name is ended by .HTM or .HTML.
But we also could as well send any request that the Server understands and that will yield back some "interesting" result: - a .SHTML page request
- a .PHP, .ASP and .ASPX request
- any file request: http://aaa.bbb.ccc/ddd/eee/fff.PDF or .TXT, or .ZIP or .JPEG
- a CGI request like http://aaa.bbb.ccc/ddd/the_cgi.exe?name=zzz which will bring back whatever the CGI author decided to send back when this request is
received by the Server
- let us also mention the special default page, which is usually denoted by "/". This request is built when the user enters the domain followed or not by a single "/" in IE's Address combo-box:
or: The user can also request the default page of some site's local path:
The Server decides which answer will be sent for an "/" or "xxx/" request. Usually, the Site creator has placed an "index.HTML" page at the root of his
site, or in each path. But other files, like "default.ASP" could be used by the Server. When the Site contains no such default page, an error is returned. In our
Site, for instance, we have an "index.HTML" at the root, but none in the local folder. The user can navigate using the menu or the "site_map.html". In any case, our project must convert requests with missing ending "/" into
the corresponding "/" request.
2.3 - Multi page download Things get a little more interesting when we try to fetch an .HTML (.HTM, .ASP etc) page AND it's associated images. The .HTML page contains anchors
referencing the images: <HTML>
<HEAD>
</HEAD>
<BODY>
<P>
This is our Pascal Institute logo:<BR>
<IMG SRC="..\_i_image\pascal_institute.png"><BR>
which is on this page
<P>
</BODY>
</HTML>
|
To get this image, we have to send a second GET request with this image address, and save this file on disc. So the basic idea is to download the HTML page, then analyze the text looking
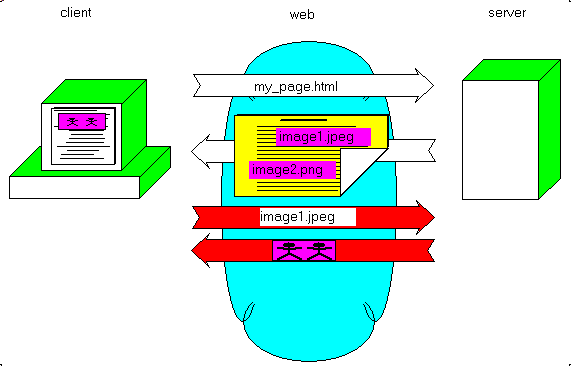
for the <IMG> tags nested in the page content, and send all the corresponding HTTP requests. So a single HTTP request looks like this: - the Client sends the request
- the Server sends the page which is displayed by the Client:
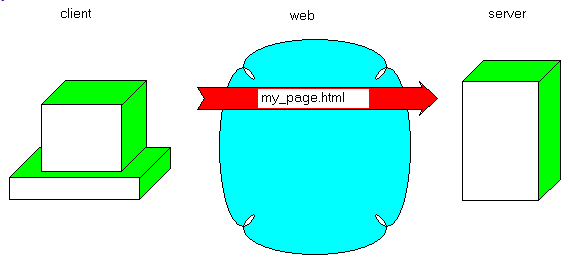
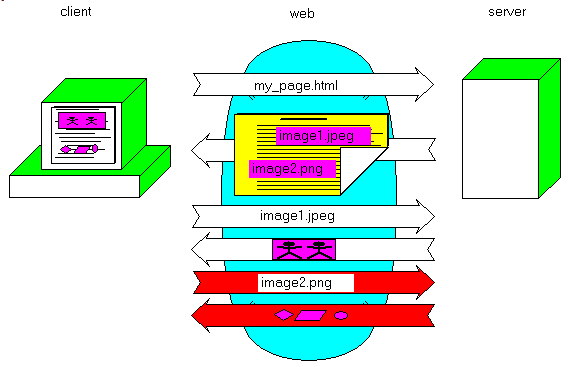
For a multiple-file request: - the Client requests the .HTML page:
- the Client analyzes the page, detects the IMG tag, sends the HTTP request,
receives the image, which is displayed by the browser:
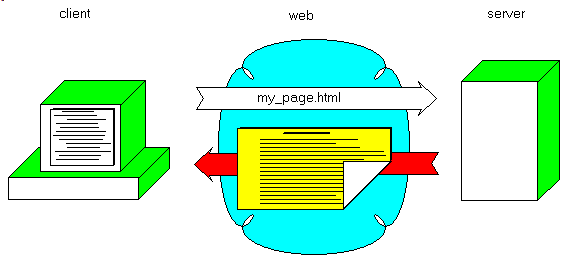
- the Client detects other IMG tags, requests and displays them:
Several hurdles soon crop up: - the .HTML syntax is not always correct, and finding the IMG tags might be difficult
- the address of the image can be absolute, relative, or even from another site
- some image references are nested within some scripting expression
2.4 - HTML parsing
It always astonished me to find out, again and again, that this very well specified format with all those nice RFC specifications full of SHOULD, COULD, WOULD, CAN, WONT etc. is so poorly implemented. Since there is no police out
there to check the syntax, everybody is free to respect or not the specification. We are not going to list all illegal constructs, but among them, let us mention:
This list goes on and on. So the difficulty is not to parse according to a specification, but to "gracefully" fall back on some sensible result. We stopped reading the specification, and somehow hacked our way to the parser used in this project.
2.5 - The address string Assuming that we managed to isolate the address string nested in an IMG tag, can we sent the HTTP request with this untouched address ? Sadly enough no, and for several reasons:
- the address in the tag might be relative to the page, and the Server will not
- there might be address aliases, several strings referencing the same Server file
- the extension is used to filter out unwanted downloads
Lets us consider the relative addresses. Here is the (partial) file structure of our site:
E:\\data\felix_pages
index.html
papers
db
oracle
oracle_db_express
oracle_db_express.html
_i_image
tnsnames.png
oracle_architecture.html
_i_image
svga_and_pmon.png
web
| Then the oracle_dbexpress.html page can reference the tnsnames.png image with The page can also reference another file in a sibbling folder:
When the address in the .HTML is relative, we cannot sent this relative address: the Server is stateless, and does not remember that we were downloading the oracle_dbexpress.html page. We must convert the address in an absolute address.
Then there are aliases: - some addresses are CGI encoded, with %nn hex codes for some non-letter characters. This often happens for ~ names:
... /personal_pages/%7EFelix/ ... standing for
... /personal_pages/~Felix/ ... and some site contains references to the same page with either %7E or ~. - in the previous example of the sibbling folder image:
../oracle_architecture/_i_image/svga_and_pmon.png if we already downloaded the image, it would be a waste of time to download it again.
And for the extension, the detection of .MOV, .WAV or .AVI files could allow us
to skip those downloads (depending on what we want to get back).
The end of the story is that we cannot avoid parsing the address. Now this parsing is not very difficult, but because of the many optional parts,
recursive descent with 1 token lookahead not possible. First some terminology. Here is a page from Scott AMBLER's site: http://www.ronin-intl.com/company/scottAmbler.html#papers We used the following names:
- http:// is the protocol
- www.ronin-intl.com is the domain name
- /company/ is the segment (we do not call it a path since it is the part of an absolute path)
- scottAmbler is the page (name)
- .html is the extension
- #papers is the target (a link to a part of the page)
And for ASP / CGI requests: http://cc.borland.com/community/prodcat.aspx?prodid=1&catid=13 - ?prodid=1&catid=13 is the cgi parameter list of this Borland Community link
Here is the EBNF syntax of the address:
url= [ protocol ] [ domain_or_ip ] [ segment ] [ page ] [ extension ] [ cgi_parameters | target ] .
protocol= ( HTTP | HTTPS | FTP ) ':' '//' | MAILTO ':' .
domain_or_ip= domain | ip .
domain= NAME '.' NAME [ '.' NAME ] .
ip= NUMBER '.' NUMBER '.' NUMBER '.' NUMBER .
segment= '/' { NAME '/' } .
page= NAME .
extension= '.' NAME .
cgi_parameters= '?' NAME '=' VALUE { '&' NAME '=' VALUE } .
targer= '#' NAME .
| And:
- the protocol is a fixed set of possible TCP/IP protocols, or MAILTO string
- the domain contains several strings (letters, digits, "_", "-") separated by dots. Note that the "www" part is often used, but some sites can be accessed
with the "www" or without
- the segment is a "/" separated NAME list, but it seems that the NAME can contain some characters illegal for DOS path names ("*")
- the page and extension are quite normal
- the cgi_parameters can be quite complex, and contain all kinds of / : ? #
Note that:
Because NAME can be the start the protocol, the domain, a relative path, or a
file name, we must use more than one symbol look ahead. Recursive descent is not the ideal candidate. A good solution would be a state machine (like for parsing REAL numbers, which also have many optional parts). The solution we are
currently using is an ad hoc hack, because we underestimated the trickiness of this simple structure parsing. Maybe one day we will replace it with a more formal parser.
2.6 - The save name
Once we have extracted the address from an .HTML tag, and added any absolute path if necessary, we can send the request to the Server. Can we then use this same name to save the page and its images on disk ?
We could, but this is far from ideal: - if the address contains characters illegal in DOS file names (presence of "?" or "*", this trigger an error.
- the same goes if the address is incomplete: when we request "/", this cannot
be a DOS file name. So we replaced those unknown names with a "NO_NAME" nickname. And since there can be several of those, we append a unique identifier.
- a simple name with an empty extension is also risky: it happened that some
page name (without extension) had the the same name as their folder. So we decided to force a .HTML (if the page contains text with some .HTML text) or a .BIN suffix
Finally, when the requested page is a deeply nested page, should we save it
with the segment or not ? Because of the possibility of "../../" addresses, we decided to keep the path structure intact. This also allows to later save other pages of the same site (spidering the site), which will be presented in the next paper.
Given the fact that we keep the path structure, but must be protected against illegal characters, we chose to "dossify" the path and name, and replace the illegal characters with "_". Since this mapping is not reversible, we uniquely
number each saved file (avoiding that aaa?bbb*ccc and aaa*bbb?ccc will be saved as the same aaa_bbb_ccc.bin file).
2.7 - Renaming the tags If we want to display the downloaded file with its images, we must rename the
image tags, replacing the site-relative names with our local names. If the image tag is already relative, the tag can be kept unchanged. But if the tag contains some absolute path, it must be converted to our disc file address.
In addition, we might have several references to the same tag in the same page (for a "top" or "home" link, for instance). To carry out this replacement, we therefore must keep the list of text positions and size of each image tag. The
replacement can then be performed after the download of the image.
3 - The Delphi Source Code 3.1 - The Delphi Structure To achieve our goal, we will need:
- a client socket
- each page is managed by a CLASS. We considered two kind of pages:
- the non-HTML pages (.GIF, .PDF etc), for which only the addresses and a buffer is necessary
- the pages containing some HTML (usually xxx.HTML or xxx.HTTP", but also "/", the answer from .PHP or .CGI requests etc): this CLASS contains a tag list, and an .HTML tag parser
- a page list is used to avoid duplicate downloads. The key to each item is the "normalized url": no %nn coding, no local path
Note that in some cases we do not know whether the Server answer will contain
.HTML or not (cgi requests for instance). We therefore will download the page as a binary page, check the page after reception, and requalify it as an .HTML page and parse it for any tags.
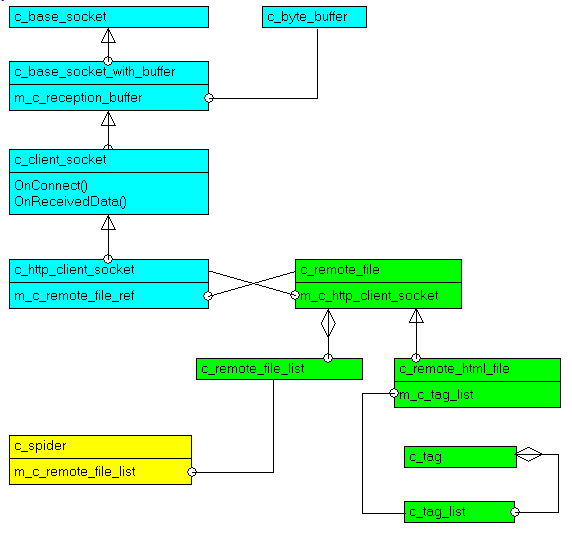
3.2 - UML Class diagram
Here is the UML Class Diagram of our project:
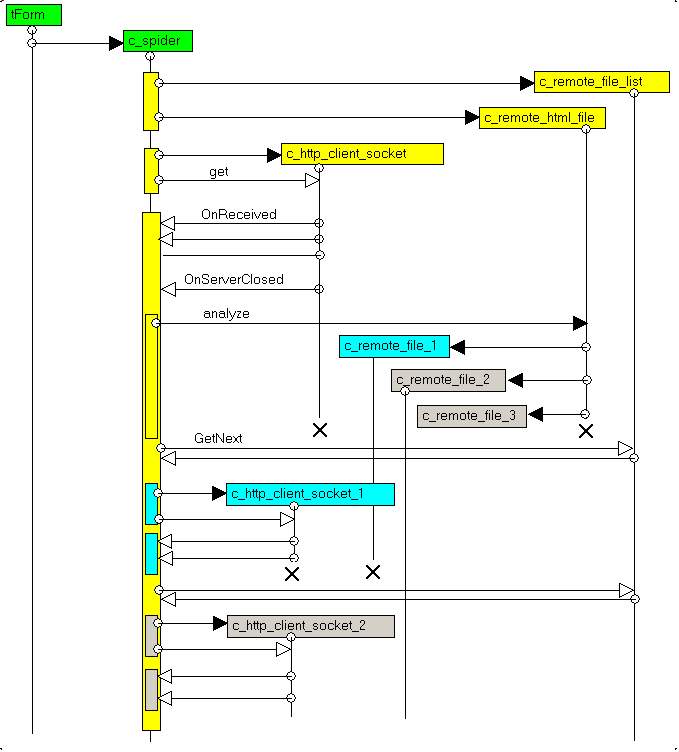
3.3 - The UML Sequence diagram Here is the UML sequence diagram:
You will see that - the user starts the c_spider, which (in yellow)
- creates the c_remote_file_list as well as the first c_remote_html_file, and starts the download of this page
- the c_http_client_socket answers back with some packets, and finishes
the download or is closed by the Server
- the c_spider then analyzes the page, building the tag list (not represented), and adding the new files to download to the
c_remote_file_list. The c_http_server_socket can then be destroyed
- the c_spider then enters a loop to
- fetch the next file (in blue, then grey)
- create the socket for this file and downloads it
3.4 - The c_spider This is the heart of our downloader. Here is the CLASS definition:
c_spider=
class(c_basic_object)
// -- the first requested url => sets the root domain+path
m_c_requested_url: c_url;
m_requested_ip: String;
m_root_save_path: String;
m_c_remove_extension_list: tStringList;
m_c_remote_file_list: c_remote_file_list;
m_on_before_download: t_po_spider_event;
m_on_received_data: t_po_spider_event;
m_on_after_save: t_po_spider_event;
Constructor create_spider(p_name, p_root_save_path: String; p_c_url: c_url);
procedure download_the_file(p_c_remote_file: c_remote_file);
procedure _handle_after_received_data(p_c_http_client_socket: c_http_client_socket);
procedure _handle_after_received_body(p_c_http_client_socket: c_http_client_socket);
procedure _handle_after_server_client_socket_closed(p_c_client_socket: c_client_socket);
procedure save_the_page(p_c_http_client_socket: c_http_client_socket);
procedure remove_other_pages;
function f_c_find_next_page: c_remote_file;
procedure replace_image_tags;
Destructor Destroy; Override;
end; // c_spider
| and for the attributes:
- m_c_requested_url contains the base request. Saving this value here allow us to implement spidering strategies (which pages should be downloaded next)
- m_requested_ip: this is filled after the first domain lookup (avoiding
further lookups when connecting to the Server)
- m_root_save_path: the start of our local copy of the site
- m_c_remove_extension_list: allows to avoid some downloads (.AVI, .MOV ...)
- m_c_remote_file_list: the files to download (avoid duplicates)
- m_on_before_download, m_on_received_data, m_on_after_save: the user notification, mainly for display purposes (current / remaining files, byte
counts etc)
In the methods, we find: - download_the_file which starts the download of a file (the first one, or the next ones)
- _handle_after_received_data, _handle_after_received_body,
_handle_after_server_client_socket_closed: the c_http_client_socket events, delegated to the c_spider to allow the fetching of the files after the first one.
The download is stopped either when Content-Length bytes have been received, or when the remote Server has closed its socket. In both cases, we call save_the_page, and the c_http_client_socket is destroyed after
this processing
- save_the_page: here
- we analyze the content of files without extensions and eventually promote them to c_remote_http_file status
- the non-html files are saved
- the .html files are parsed for any anchor tag. The anchors are added to the c_remote_file_list and the page is saved
- the next page is fetched from the c_remote_file_list, and
download_the_file called with this new page, if any
- remove_other_pages: this method eliminates the files we do not want to download (other site pages, .AVIs etc)
- f_c_find_next_page: the function implements the download order strategy: first the .GIF, then the .PDF etc
- replace_image_tags: after all files have been downloaded, we replace the
first page's IMG tags with their local disc address tag
Let us now quickly look at the other CLASSEs.
3.5 - The sockets
We used our own socket classes (see the simple_web_server paper). You can replace them with other Client sockets (Delphi tClientSocket, Indy, Piette's ICS, Synapse etc.). In our case
- the c_client_socket allows to lookup the domain, connect to the Server, send the GET string, and receive the packets. This socket has already been presented
- the c_http_client_socket is specialized to save and analyze the HTTP answer header (mainly the error code: "HTTP/1.1 200 OK" and the "Content-Length=nn" if any)
Here is the definition:
c_http_client_socket=
class(c_client_socket)
m_get_request: String;
m_requested_page: String;
// -- for debug display. "200 ..."
m_end_of_header_index: Integer;
// -- from the answer header
m_content_length: Integer;
// -- how much was received beyond the header
m_downloaded_content_length: Integer;
m_on_http_connected: t_po_http_event;
m_on_http_received_data: t_po_http_event;
m_on_after_received_http_body: t_po_http_event;
Constructor create_http_client_socket(p_name: String);
procedure lookup_connect_get(p_server_name: String;
p_port: Integer; p_get_request: String);
procedure connect_get(p_ip_address: String;
p_port: Integer; p_get_request: String);
procedure connect_server_name(p_server_name: String; p_port: Integer);
procedure _handle_after_lookup(p_c_client_socket: c_client_socket);
procedure connect_ip(p_ip_address: String; p_port: Integer);
procedure _handle_http_connected(p_c_client_socket: c_client_socket);
procedure _handle_received_data(p_c_client_socket: c_client_socket);
end; // c_http_client_socket
| Note that
- lookup_connect_get and connect_get are the high level method, which then call the low-level lookup, CreateSocket, Connect etc
3.6 - The c_url CLASS
To save the URL parts, we use the c_url CLASS:
c_url= class(c_basic_object)
// -- m_name: the url
m_protocol, m_domain, m_segment,
m_page, m_extension, m_cgi_parameters, m_target: String;
Constructor create_url(p_name: String);
procedure decompose_url_0;
function f_decompose_url: Boolean;
function f_display_url: String;
function f_display_url_short: String;
function f_is_html_extension: Boolean;
function f_c_clone: c_url;
function f_c_normalized_url: c_url;
function f_c_dos_save_names: c_url;
end; // c_url
| where:
- m_protocol, m_domain, m_segment, m_page, m_extension, m_cgi_parameters, and m_target are the address part
- f_decompose_url is our hand crafted parser
- f_is_html_extension tells whether the extension is a potential HTML content (.HTML, .ASP etc)
- f_c_clone is used when we transfer the URL from the tag list to the c_remote_file list
- f_c_normalized_url: clones the URL after removing %nn hex characters.
- f_c_dos_save_names: clones the URL and dossifies the names (changes / into \, remove illegal DOS characters like * or ? etc. The DOS name does not
contain the target or cgi_parameter parts (we could use it though).
We use this CLASS: - when the user types the target path in the tForm Edit
- when we found an anchor tag in the .HTML page. In this case, we compute the normalized url (no %nn), make sure that the address is absolute (not relative to the current page) and that there are no remaining path dots (..
or .). This result, is then used as a key in the c_remote_file_list to avoid duplicate downloads. We do not use the dos name as a key, since this has been even more transformed (removing * ? etc).
3.7 - The c_remote_file The definition of the CLASS is: c_remote_file=
Class(c_basic_object)
m_c_parent_remote_file_list: c_remote_file_list;
m_c_url: c_url;
// -- remove %nn, HOME_absolute
m_c_normalized_url: c_url;
// -- no \, remove spaces, ? *, no target or cgi parameters
m_c_dos_save_names: c_url;
m_c_http_client_socket: c_http_client_socket;
// -- all saved, analyzed
m_downloaded: Boolean;
// -- only try to get once
m_trial_count: Integer;
// -- do not try to download those (other domains, avi ...)
m_do_download: Boolean;
// -- update display on next event
m_already_displayed: Boolean;
// -- to check consistency with saved
m_did_get: Boolean;
// -- if analyses when content received, avoid doing it when server_closes
m_saved: Boolean;
// -- the unique name on disc, used to replace the image tags
m_saved_name: String;
Constructor create_remote_file(p_c_url, p_c_normalized_url: c_url);
function f_display_remote_file: String;
function f_c_self: c_remote_file;
procedure save_file(p_full_file_name: String);
Destructor Destroy; Override;
end; // c_remote_file
| Each c_remote_file contains its own m_c_http_remote_socket, which is used to
download the data. This socket is used to send the GET request, and then loads the data retrieved in its buffer. We delegated the socket reception events to the c_spider, since we want to
communicate the data arrival to the main Form. After sending the GET request, the Winsock library will send FD_READ events, which were transformed in on_data_received Delphi events. Those events only have a c_http_client_socket
parameter, not a c_remote_file parameter. We make the link with the c_remote_file using a general purpose m_c_object attribute in the c_client_socket CLASS, since this reference from the socket to the object
owning the socket often arises in client socket application. In our case, the c_spider - created a c_remote_file object
- created its m_c_http_client_socket, and initialized
m_c_http_client_socket.m_c_object with the c_remote_file
3.8 - The c_remote_html_file This class also includes the .HTML parser which extracts the anchor tags:
c_remote_html_file=
Class(c_remote_file)
m_c_text_buffer: c_text_buffer;
m_c_tag_list: c_tag_list;
Constructor create_remote_html_file(p_c_url, p_c_normalized_url: c_url);
function f_c_self: c_remote_html_file;
procedure copy_data_to_c_text_buffer(p_pt: Pointer; p_length: Integer);
procedure analyze_text_buffer(p_c_text_buffer: c_text_buffer;
p_c_log_all_tag, p_c_log_tag_analysis: c_log);
procedure load_from_file(p_path, p_file_name: String);
procedure replace_image_tags_in_html;
end; // c_remote_html_file
| and:
- copy_data_to_c_text_buffer : we decided to use our c_text_buffer CLASS for ease of parsing (this allows easy string extraction, comparison etc). So this method copies the byte buffer received from the Server into a text
buffer.
- load_from_file: allows loading .HTML files from disc to perform the tag parsing (debugging, later image download etc)
- replace_image_tags_in_html : this is a simple tag replacement. We assumed
that the tags were unique, and the method must be manually called from the main tForm after all downloads. The method simply scans the tag list, and if any of them is an image tag, and the image was downloaded, the address is
replaced with a disc address
3.9 - The tag list The tags collected from an .HTML page are defined by:
t_tag_type= (e_unknown_tag,
// -- "<A HREF="yyy.html" uuu>"
e_anchor_tag,
// -- <FRAME SRC= ...
e_frame_tag,
// -- <IMG ...
e_image_tag,
e_end_tag);
c_tag= // one "tag"
Class(c_basic_object)
// -- m_name: the attributes
// -- index in the text (for anchor change)
m_attributes_start_index: Integer;
// -- the attributes (debug, check before replace)
m_attributes: string;
// -- anchor, frame, image
m_tag_type: t_tag_type;
// -- the tag as contained in the page
m_c_url: c_url;
// -- if no domain or segment, add the parent's segment ...
m_c_normalized_url: c_url;
Constructor create_tag(p_name: String;
p_text_index, p_attributes_start_index: Integer; p_attributes: string;
p_tag_type: t_tag_type;
p_c_url, p_c_normalized_url: c_url);
function f_c_self: c_tag;
function f_display_tag: String; Virtual;
Destructor Destroy; Override;
end; // c_tag
c_tag_list= // "tag" list
Class(c_basic_object)
m_c_tag_list: tStringList;
Constructor create_tag_list(p_name: String);
function f_tag_count: Integer;
function f_c_tag(p_tag_index: Integer): c_tag;
function f_c_add_tag(p_tag: String; p_c_tag: c_tag): c_tag;
function f_c_add_tag_element(p_tag: String;
p_text_index, p_attributes_start_index: Integer; p_attributes: string;
p_tag_type: t_tag_type;
p_c_url, p_c_normalized_url: c_url): c_tag;
procedure display_tag_list;
Destructor Destroy; Override;
end; // c_tag_list
|
3.10 - The main form
Our main form contains the tEdit where we can type (or paste) the target URL, and several displays (list of files to download, discarded files, downloaded files with status) and debugging display (trace of the socket calls etc).
Here is a snapshot of this window, when we request Scott AMBLER's page: 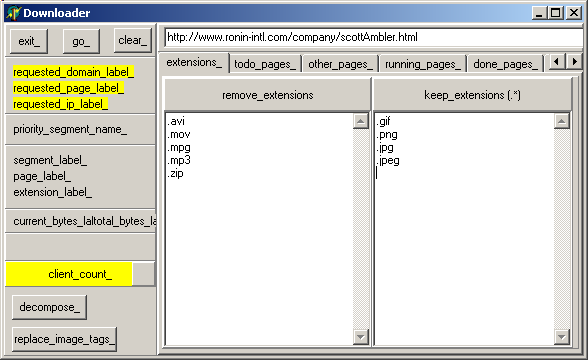
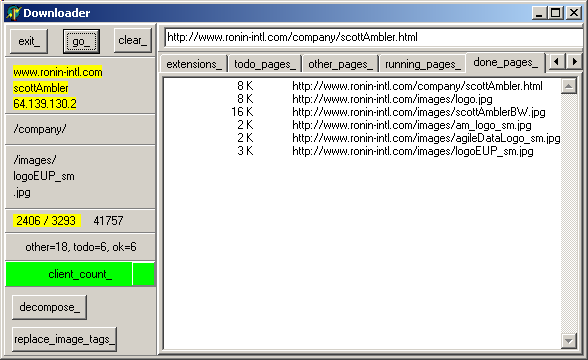
When we click "Go", the following pages are downloaded:
 and here are the rejected pages: 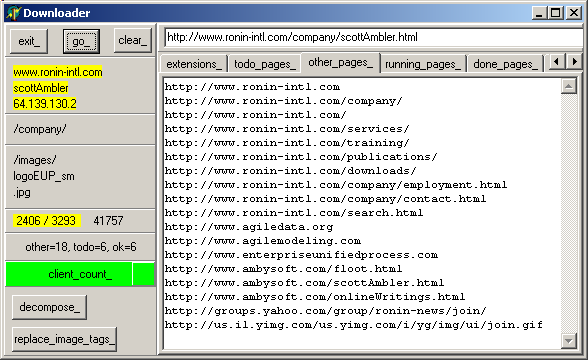
We then click "replace_image_tags_", and, going in our save folder, when we click on "scottAmbler__0.html", this is what we get: 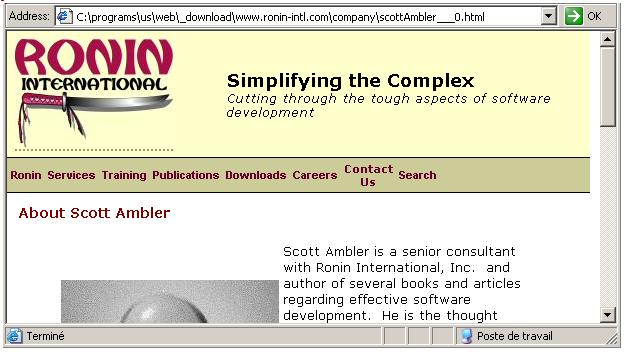
You might have noticed that although the requests segment was "/company/", the downloader created the sibbling path "/images/" where the pictures were saved. The rejected page list shows the pages references in the requested page but not
matching our download criteria.
4 - Possible Improvements There are many features that can be added to this simple downloader: - for the user aspect:
- make the page selection more user friendly
- for the downloading
- send all the download request as soon as they can be sent. In our case, we cautiously wait for one page to be downloaded before starting the next
download. Using asynchronous sockets does not require this
- add an "abort" possibility (actually the program bombs when stopping it with still active sockets)
- save the original URL in a comment in the saved text. IE does this, and
we found this quite convenient, since it allows to get the original page back if required
- we know that .HTML allows the <BASE> tag allowing to factor out the base
part of a tag to allow dereferencing local pathes (a kind of WITH), but we did not take this into account
- for the display:
- display the page. This would require analysis of ALL tags (not only the
anchors) and the HTML rendering (displaying the text and image according to the .HTML page). Including an HTML renderer would transform our downloader into a full fledged browser
5 - Download the Sources Here are the source code files:
Those .ZIP files contain:
- the main program (.DPR, .DOF, .RES), the main form (.PAS, .DFM), and any other auxiliary form
- any .TXT for parameters
- all units (.PAS) for units
Those .ZIP
- are self-contained: you will not need any other product (unless expressly mentioned).
- can be used from any folder (the pathes are RELATIVE)
- will not modify your PC in any way beyond the path where you placed the .ZIP
(no registry changes, no path creation etc).
To use the .ZIP: - create or select any folder of your choice
- unzip the downloaded file
- using Delphi, compile and execute
To remove the .ZIP simply delete the folder.
As usual: - please tell us at fcolibri@felix-colibri.com if you found some errors, mistakes, bugs, broken
links or had some problem downloading the file. Resulting corrections will be helpful for other readers
- we welcome any comment, criticism, enhancement, other sources or reference
suggestion. Just send an e-mail to fcolibri@felix-colibri.com.
- or more simply, enter your (anonymous or with your e-mail if you want an
answer) comments below and clic the "send" button
- and if you liked this article, talk about this site to your fellow
developpers, add a link to your links page ou mention our articles in your blog or newsgroup posts when relevant. That's the way we operate: the more traffic and Google references we get, the more articles we will write.
6 - Conclusion This paper presented a simple web downloader allowing to save on disc an .HTML page and its related images. You can then use Internet Explorer as an off-line reader.
7 - The author
Felix John COLIBRI works at the Pascal Institute. Starting with Pascal in 1979, he then became involved with Object Oriented Programming, Delphi, Sql, Tcp/Ip, Html, UML. Currently, he is mainly
active in the area of custom software development (new projects, maintenance, audits, BDE migration, Delphi
Xe_n migrations, refactoring), Delphi Consulting and Delph
training. His web site features tutorials, technical papers about programming with full downloadable source code, and the description and calendar of forthcoming Delphi, FireBird, Tcp/IP, Web Services, OOP / UML, Design Patterns, Unit Testing training sessions.
|