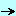|
AJAX Tutorial - Felix John COLIBRI. |
- abstract : writing an AJAX web application. How AJAX works, using a JavaScript DOM parser, the Indy Web Server, requesting .XML data packets - Integrated development project
- key words : AJAX - XMLHttpRequest - XML DOM - DOM parser - Indy tIdHttpServer - tWebBrowser
- software used : Windows XP Home, Delphi 6, Indy 8.5, Internet Explorer 6.0
- hardware used : Pentium 2.800Mhz, 512 M memory, 140 G hard disc
- scope : Delphi 1 to 2006, Turbo Delphi for Windows, Delphi 2007, RAS Studio 2007
- level : Delphi developer
- plan :
1 - Why use AJAX technology
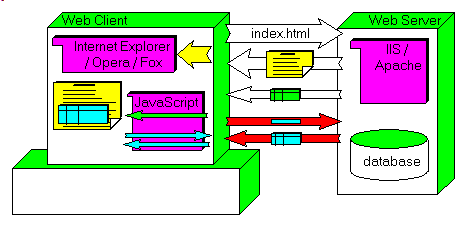
AJAX (Asynchronous JAvascript and Xml) is the new buzz word those days. This technique allows to grab data from the Server and refresh the page without having to reload the full page content (images, music, flash animations
etc). For pages with heavy overhead and many data refresh, it becomes more efficient to load the background page and the multiple data requests separately. And this can be done using AJAX.
2 - Simple AJAX implementation 2.1 - How AJAX works The usual way of operations of a site is to write pages with many links between
them letting the user navigate in your site. Whenever the user clicks on a link, there is a round trip to sent the URL and get the pages which is displayed in the Browser
When a page contains some data which can change, like a DataGrid with paging, whenever the user wants the next page of data, the whole page is built by the Server and reloaded (that is analyzed, displayed) by the Browser:
So even if some pieces (images) are cached by the Browser, the Browser still has to analyze and layout the page, even if only a couple of strings have changed in the display Here is an illustration of the standard way of operating:
- the user requests some page with the first rows of some data table
- when the user request the next data pieces, the new requests brings the
whole page back, with the new data:
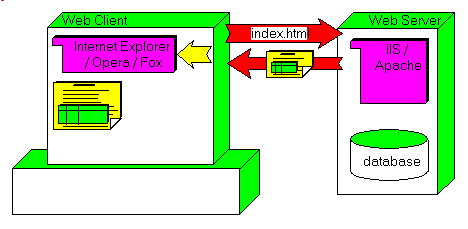
To avoid the multiple transfer of the background page, the basic idea of AJAX
is to decouple the data-loading part from the overall page To do so, AJAX relies basically on 2 JavaScript techniques - the ability to request only data from the Server, which is done using an XMLHTTPRequest call
- grafting some parts in page analyzed and displayed by the Browser, using innerHTML or similar technique
This can be illustrated like this - the first request loads the base page:
- when the second and next data pieces are requested (paging in a DataGrid, for instance), only the data payload is transferred from the Server:
Note that - for the first page, we could use the standard "page+data" transfer. In our illustration, we assumed that even for the first page the data was loaded
separately. But of course, this is not mandatory.
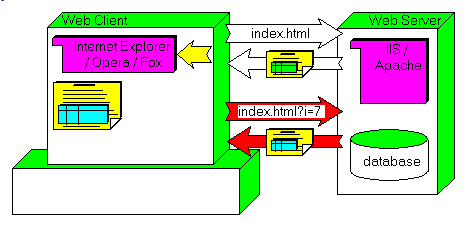
2.2 - Our AJAX example We will present our first AJAX example on an ARTICLE_LIST.HTML page:  |
the user requests our ARTICLE_LIST page
|  | our server returns the page with the first 4 article rows
| |
| the user clicks the "next_article" link
| | | the next 4 article rows are fetched and displayed
|
2.3 - JavaScript Crash Course To be able to able to implement our AJAX machinery, we must have an elementary understanding of JavaScript and DOM (Document Object Model).
2.3.1 - Javascript: a Client Side Interpreter Without any scripting, our pages are built on the Server and clicking on a link simply sends the corresponding URL to the Server referenced in this link.
No activity other than rendering the page is performed by the Client Browser: no mouse event, no client area keyboard event, no nothing. Enters JavaScript: a client side interpreter which can execute scripts which
are sent from the Server to the Client along with the main .HTML. Those scripts are able to execute code statements, among which - do some event handling for mouse events
- call some routine when the user click on an hyperlink.
2.3.2 - OnClick With JavaScript, the main feature is to be able do click on a link on our page and call a routine which does some handling.
For instance, to change the color of a .HTM page in red when the user click the "red" link: - we identify the area which should be modified with a unique ID
- we create a SCRIPT tag containing a routine which finds the area to paint, and changes its color style attribute
- we create a link which, when clicked, will call the JavaScript routine
Here is the example: <HTML>
<HEAD>
</HEAD>
<BODY ID="my_body">
| <SCRIPT>
function set_color()
{
document.getElementById("my_body").style.backgroundColor = "red";
}
</SCRIPT>
|
<A HREF="#" ONCLICK="javascript: set_color(); return false;">red</A><BR>
</BODY>
</HTML>
|
| and
- our BODY tag contains an ID attribute with our "my_body" unique identifier
- the SCRIPT tag contains the color changing routine
- the hyperlink "red" is defined by the usual A anchor tag, which contains a call to our coloring routine
with the corresponding snapshot : 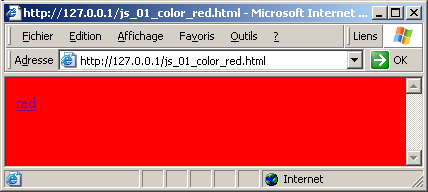
To run this example, you may | | copy the text to the ClipBoard
| |
| start NotePad, paste the code
| | | "save as" with an .HTML extension
|
| | double click on the disc file, and let Internet Explorer display the result
|
CAUTION
- the .HTML tag name (like BODY) and attribute name (like HREF) are case insensitive. It seems that the specification requires uppercase,
but nobody follows this anyway, so most of the browser have learned to live with this
- the JavaScript language on the other hand IS CASE SENSITIVE and writing
BackgroundColor usually will not work. In addition most of the names follow the Java convention: first lowercase and additional names with a first capital. Like getElementById
2.3.3 - Unique tag ID s In order to change the style or content of a tag: - we simply include an ID attribute with a unique value
- we access this value using
my_element = Document.getElementById(my_id_value); |
and
- the full .HTML page is the Document JavaScript object
- this object has attributes and methods, and the getElementById is a search
function returning the object with this ID. So the result is another JavaScript object
- the returned object in turn has attributes and methods. In our example, we used the style attribute
- we could have used other attributes
Here is an example where we attach IDs to some other tags, and toggle their color values between yellow and white:
<HTML>
<BODY ID="my_body">
| <SCRIPT>
function set_element_color(p_element_id)
{
l_c_element= document.getElementById(p_element_id);
if ( l_c_element.style.backgroundColor == "yellow" )
l_c_element.style.backgroundColor= "white";
else l_c_element.style.backgroundColor= "yellow";
} // set_element_color
</SCRIPT>
|
<DIV>
<A href="#" onClick="set_element_color('my_body')">form_color</A><BR>
<A href="#" onClick="set_element_color('my_div')">div_color</A><BR>
<A href="#" onClick="set_element_color('my_cell')">cell_color</A><BR>
<A href="#" onClick="set_element_color('button_id')">button_color</A><BR>
</DIV>
<HR>
<DIV ID="my_div">
this is a div
<TABLE border= 2>
<TR>
<TD ID="my_cell">
cell_0_0
</TD>
<TD>
cell_0_1
</TD>
</TR>
</TABLE>
</DIV>
<DIV>
<FORM>
<INPUT TYPE="button" ID="button_id" VALUE="my_button" />
</FORM>
</DIV>
</BODY>
</HTML>
|
| with the following snapshot : 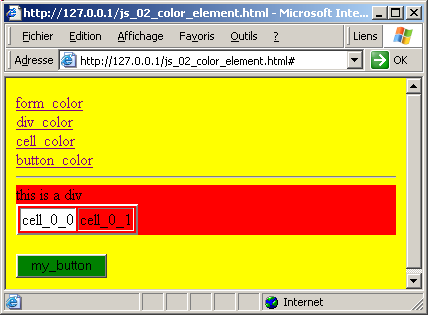
2.3.4 - Replace a content: innerHTML We simply changed the color, but there are other possibilities. For our AJAX
implementation, we will replace some data elements with new data elements. Reading or writing an element is performed using the innerHTML attribute. In the following example, clicking "text" will add "AHA" and clicking "table"
will add a table: <HTML>
<HEAD>
</HEAD>
<BODY>
|
<SCRIPT>
function replace_element(p_id, p_replacement)
{
document.getElementById(p_id).innerHTML =
document.getElementById(p_id).innerHTML
+ p_replacement;
}
</SCRIPT>
| <DIV>
<A HREF="#" ONCLICK="javascript: replace_element('div_id',
'aha');">text</A><BR>
<A HREF="#" ONCLICK="javascript: replace_element('div_id',
'<TABLE border=2><TR><TD>table</TD></TR></TABLE>');">
table</A><BR>
</DIV>
<DIV ID="div_id">
original content
</DIV>
</BODY>
</HTML>
|
|
If we clic "table", "text", "text", we will get: 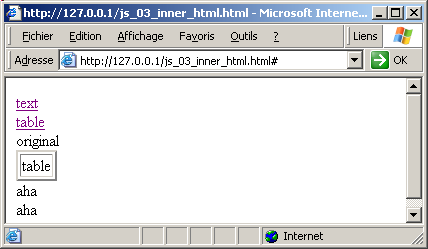
Please note
- this is, in fact, the easiest way to build a debugging log on a Page: just add a DIV tag and append text using innterHTML.
- innerHTML seems to be frowned at by some JavaScript developers, and the argument seems to be "making a mistake in the replacement could break the page". Well, if writing bugs would have deterred us from programming ...
2.4 - Reading .XML from the Server JavaScript also allows to request some file from the Server: - we must create an xmlhttprequest object which can be native or an ActiveX component
var my_c_xml_http_request;
if (window.xmlhttprequest)
{
// -- use Native XMLHttpRequest
my_c_xml_http_request = new xmlhttprequest();
}
else
if (window.activexobject)
{
// -- use IE/Windows ActiveX
my_c_xml_http_request = new activexobject("Microsoft.XMLHTTP");
}
if (my_c_xml_http_request == null)
alert("does not support xml_http_request");
| - we use this object to call open and send
// -- prepare the GET
my_c_xml_http_request.open("GET", '/my_data.xml', true);
// -- request the file by sending the GET
my_c_xml_http_request.send(null);
| This works, but after the send call, the data is not transferred on the spot: there is a call to the Server, which might have some delay, or the
line could be slow. Therefore, to synchronize the reception, xmlhttprequest has a callback, called onreadystatechange in which we can test the xmlhttprequest.readyState: a value of 4 means that the .XML has been received.
Therefore, the retrieval should use some code like:
function on_readystate_change()
// -- called once the .XML has been received
{
if (my_c_xml_http_request.readystate == 4)
{
// -- the download is finished
if (my_c_xml_http_request.status != 200)
alert('error loading HML file. Status: '
+ my_c_xml_http_request.status + ' '
+ my_c_xml_http_request.statustext);
// -- do some handling on
// -- my_c_xml_http_request.responseText;
}
else
{
// -- tell the user that the transfer is
// -- proceeding
}
} // on_readystate_change
// -- set the state change handler
my_c_xml_http_request.onreadystatechange = on_readystate_change;
// -- prepare the GET
my_c_xml_http_request.open("GET", '/my_data.xml', true);
// -- request the file by sending the GET
my_c_xml_http_request.send(null);
|
Putting this together on our page will yield:
<HTML>
<HEAD>
|
<SCRIPT>
function load_xml(p_xml_file_name)
{
var l_c_xml_http_request;
function create_xml_http_request()
{
if (window.XMLHttpRequest)
{
// -- use Native XMLHttpRequest
l_c_xml_http_request = new XMLHttpRequest();
}
else
if (window.ActiveXObject)
{
// -- use IE/Windows ActiveX
l_c_xml_http_request = new ActiveXObject("Microsoft.XMLHTTP");
}
if (l_c_xml_http_request == null)
alert("does not support xml_http_request");
} // create_xml_http_request
function get_and_parse_xml()
{
// -- set the state change handler
l_c_xml_http_request.onreadystatechange = on_readystate_change;
// -- prepare the GET
l_c_xml_http_request.open("GET", p_xml_file_name, true);
// -- request the file by sending the GET
l_c_xml_http_request.send(null);
} // get_and_parse_xml
function on_readystate_change()
// -- called once the .XML has been received
{
l_memo_ref= window.document.display_form.display_memo;
if (l_c_xml_http_request.readyState == 4)
{
// -- the download is finished
if (l_c_xml_http_request.status != 200)
alert('error loading HML file. Status: '
+ l_c_xml_http_request.status + ' '
+ l_c_xml_http_request.statusText);
// -- display the .XML as text
l_memo_ref.value += l_c_xml_http_request.responseText;
}
else
{
l_memo_ref.value += "processing: readyState "
+ l_c_xml_http_request.readyState+ '...');
}
} // on_readystate_change
// -- main body of load_xml
create_xml_http_request();
get_and_parse_xml();
} // load_xml
</SCRIPT>
| </HEAD>
<BODY>
<DIV>
<A HREF="#" onClick="load_xml('/articl_list.xml');">display_ok</A><BR>
<DIV>
<DIV>
<FORM NAME="display_form">
<TEXTAREA NAME="display_memo" ROWS=10 COLS=60></TEXTAREA>
</FORM>
</DIV>
</BODY>
</HTML>
|
|
Note that - in the previous example, we placed the SCRIPT tag within the
HEAD tag (instead of in the BODY section). Both are accepted, and we can even use several SCRIPT sections, both in HEAD or
BODY. And when our trials are finished, we could also externalize the whole script in an external .JS file
- our Page contains a TEXTAREA memo for displaying the text of the
received .XML. This is where the innerHTML could disrupt the .HTML Page: the .XML contains tags, which usually have nothing to do whith bona fide .HTML tags
- but what exactly is is the .XML ? That depends on what the Server answers when it gets the .XML request. And this is our next step.
2.5 - Building an .HTTP Server 2.5.1 - The .XML request
When we call xmlhttprequest.send(), this will send exactly the following .HTTP request on the wire (Ed: the direction => and the User-Agent line break added):
=> GET /article_list.xml HTTP/1.1
=> Accept: */*
=> Accept-Language: eng-us
=> Referer: http://192.168.0.2/get_article_list.html
=> Accept-Encoding: gzip, deflate
=> User-Agent: Mozilla/4.0 (compatible; MSIE 6.0;
Windows NT 5.1; SV1; .NET
CLR 2.0.50727)
=> Host: 192.168.0.2
=> Connection: Keep-Alive
=> |
And the Server should send back something like:
<= HTTP/1.1 200 OK
<= Server: my_server
<= Content-Type: text/xml
<= Content-Length: 282
<=
<= <xml>
<= <updated>01 October 2007</updated>
<= <articles>
<=
<article id="063" title="Ajax Tutorial" date="1/oct/2007" />
<= <article id="062"
title="BlackfishSql" date="24/sep/2007" />
<= <article id="061"
title="Dbx4 Programming" date="19/sep/2007" />
<= </articles>
<= </xml> |
2.5.2 - The .HTTP Server As a Server, we have many possible choices, from the simple socket home grown Server up to an IIS CGI or ISAPI extension (Microsoft Internet Information Server CGI / ISAPI).
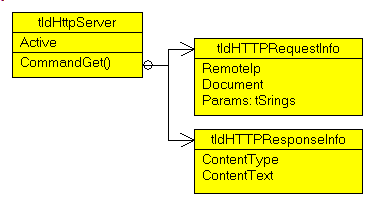
Since the purpose of this article is not .HTTP Server implementation, we will use the Indy tIdHTTPServer which comes with Delphi. This Server is quite easy to use: - toggle Active to True
- create the CommandGet event and build the response
The syntax of this response event is:
procedure IdHTTPServer1CommandGet(AThread: TIdPeerThread;
RequestInfo: TIdHTTPRequestInfo;
ResponseInfo: TIdHTTPResponseInfo);
| Our Server will be called two times:
- when the user requests the INDEX.HTML home page
- when the user clicks the link to get the ARTICLE_LIST.XML
Therefore in the response, we must consider both cases. The response.Document
is the page requested by the user, and this is either our ARTICLE_LIST.XML request, or the INDEX.HTML. So a simple test on Document will be sufficient. Depending on the Document, we either load the INDEX.HTML, or build the .XML string
Here are all the Indy components and properties we will use:
Here is our complete Server |
| select "File | New | Application" and save it as AJAX_TUTORIAL
| | | from the "Indy Servers" tab of the Tools Palette, select the
tIdHTTPServer:  and drop it on the tForm
| | |
add a tButton an toggle IdHTTPServer.Active to True, which will start the Server listening
| | |
create the CommandGet event, and write the code which will build the response to the possible requests (the initial .HTML and the .XML article list):
procedure TForm1.IdHTTPServer1CommandGet(AThread: TIdPeerThread;
RequestInfo: TIdHTTPRequestInfo; ResponseInfo: TIdHTTPResponseInfo);
function f_build_static_response(p_requested_document: String): String;
var l_file_name, l_new_file_name: String;
l_index: Integer;
begin
// -- convert all '/' to '\'
l_file_name:= f_replace_character(p_requested_document, '/', '\');
// -- locate requested file
l_file_name:= g_path+ l_file_name;
if AnsiLastChar(l_file_name)^= '\'
then // -- folder - reroute to default document
l_new_file_name:= l_file_name+ g_file_name
else // -- a file request: use this file name
l_new_file_name:= l_file_name;
if FileExists(l_new_file_name)
then Result:= f_load_string(l_new_file_name)
else begin
// -- some error
display_bug_stop('not_found '+ l_new_file_name);
end;
end; // f_build_static_response
function f_xml_response(p_request_command: String;
p_c_request_params: tStrings): String;
var l_row_index: Integer;
l_start_index, l_row_count: Integer;
begin
with tStringList.Create do
begin
Add('<xml>');
Add(' <updated>01 October 2007</updated>');
Add(' <articles>');
Add(' <article id="063" title="Ajax Tutorial"'
+ ' date="1/oct/2007" />');
Add(' <article id="062" title="BlackfishSql"'
+ ' date="24/sep/2007" />');
Add(' <article id="061" title="Dbx4 Programming"'
+ ' date="19/sep/2007" />');
Add(' </articles>');
Add('</xml>');
Result:= Text;
Free;
end; // with tStringList.Create
end; // f_xml_response
var l_requested_document: String;
l_extension: String;
begin // IdHTTPServer1CommandGet
l_requested_document:= RequestInfo.Document;
// -- either load a static page, or build a dynamic .XML response
if l_requested_document = '/article_list.xml'
then begin
ResponseInfo.ContentType:= 'text/xml';
ResponseInfo.ContentText:=
f_xml_response(l_requested_document, RequestInfo.Params);
end
else begin
// -- build 'Content-Type header"
l_extension:= ExtractFileExt(l_requested_document);
display('Ext '+ l_extension);
if l_extension= '.css'
then ResponseInfo.ContentType:= 'text/css'
else
if l_extension= '.js'
then ResponseInfo.ContentType:= 'text/javascript'
else ResponseInfo.ContentType:= 'text/html';
ResponseInfo.ContentText:=
f_build_static_response(l_requested_document);
end;
end; // IdHTTPServer1CommandGet
|
| | | compile, run and click "active" to start the Server
| | |
start Internet Explorer and request
http://127.0.0.1/index.html | | |
the page with the "article_list" link is displayed
| | | click this link
| |
| the .XML file is displayed in the TEXTAREA: 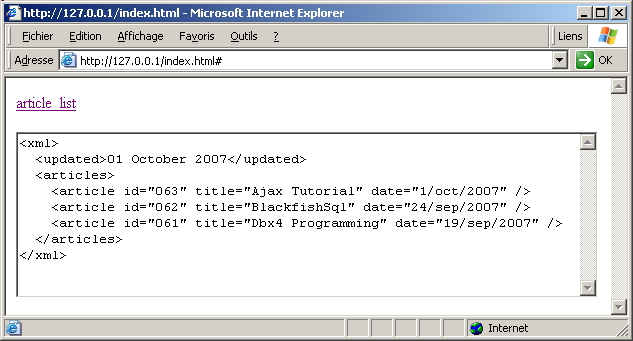
|
Note that
- we built the .XML entirely from code. This could have been loaded from some text file, or, better, from a database
- you will notice that we also would have served .CSS and .JS files, if our INDEX.HTML had referenced such files
2.6 - Analyzing the response .XML In the previous example, we have displayed the .XML as text. We must extract the values from this .XML in order to display it in a more friendly manner. In
addition, we could perform other transformations, like pagination, filtering or column selection. To be able to handle the .XML tree : - the .XML response MUST have a "Content-Type : text/xml" value
- we must drill down into the .XML using the .DOM (Document Object Model) INTERFACE available in JavaScript
2.6.1 - Extracting the .XML values First lets extract the .XML values.
In our case, the .XML was:
<xml>
<updated>01 October 2007</updated>
<articles>
<article id="063"
title="Ajax Tutorial" date="1/oct/2007" />
<article id="062" title="BlackfishSql" date="24/sep/2007" />
<article id="061" title="Dbx4 Programming" date="19/sep/2007" />
</articles>
</xml>
| and we would like to display something perhaps like this :
Last Updated : 01 October 2007
Article List:
063 Ajax Tutorial [01/oct/2007]
062 BlackfishSql [24/sep/2007]
061 Dbx4 Programming [19/sep/2007] |
To extract the .XML values - we get an .XML document object
my_c_xml_node = my_c_xml_http_request.responseXml;
| - to navigate this tree, we can use
- my_c_node.firstChild to get one level down
- my_c_node.nextSibling to get the neighbouring node
- my_c_node.getElementsByTagName('my_tag') to get a list of nodes with some tag name. This list can be explored using length and indexing into the list
Nodes are of different types. We are mainly interested in - my_c_node.nodeType 1 which is a so called "element", which can have attributes
<article id="062" title="BlackfishSql" date="24/sep/2007" />
| and: - "article" is a type 1 "element", with attributes "id", "title" and "date"
- my_c_node.nodeType 3, a "text" node, with a my_c_node.Data text content
<updated>01 October 2007</updated>
| and: - "updated" is an "element" (type 1)
- ITS CHILD is the "text" (type 3) with content "01 October 2007"
To make this clear, we wrote a small recursive routine which displays the information for each node:
function display_xml_node(p_c_xml_node)
{
if (p_c_xml_node)
{
l_text= 'node_name '+ p_c_xml_node.nodename
+ ' node_type '+ p_c_xml_node.nodetype
+ ' '+ p_c_xml_node.nodetypestring;
l_node_type= p_c_xml_node.nodetype;
if (l_node_type== 1)
{
// -- an "ELEMENT"
} ;
else
if (l_node_type==3 || l_node_type==4)
{
l_text+= ' ['+ p_c_xml_node.data+ ']';
} ;
l_c_attribute_list= p_c_xml_node.attributes;
if (l_c_attribute_list)
{
l_attribute_count= l_c_attribute_list.length;
if ( l_attribute_count )
{
l_text += ' attr_cnt='+ l_attribute_count+ ' [';
for (var l_index= 0; l_index< l_attribute_count; l_index ++ )
{
l_c_attribute= l_c_attribute_list[l_index];
if ( l_c_attribute.nodevalue != null )
l_text += ' '+ l_c_attribute.name+ '= '
+ l_c_attribute.nodevalue;
}; // for l_index
l_text += ']';
}; // has attributes
else l_text+= ' []';
} ;
else l_text += ' no_attr';
do_display(l_text);
}
else do_display('node_NULL');
} // display_xml_node
function display_xml_tree_recursive(p_c_xml_node)
{
do_display('> recurse ');
while (p_c_xml_node)
{
display_xml_node(p_c_xml_node);
// -- recurse down
l_c_first_child= p_c_xml_node.firstchild;
if (l_c_first_child)
display_xml_tree_recursive(l_c_first_child);
// -- get the next sibbling
p_c_xml_node = p_c_xml_node.nextsibling;
}; // while
do_display('< recurse');
} // display_xml_tree_recursive
display_xml_tree_recursive(my_c_xml_http_request.responsexml);
|
where do_display() is the JavaScript version of our traditional indented log. This log JavaScript is in the source .ZIP which comes with this article. Here is the result with our .XML example (as copied from the TEXTAREA log memo):
> on_readystate_change
readyState 4
> recurse
node_name #document node_type 9 document no_attr
> recurse
node_name xml node_type 1 element []
> recurse
node_name updated node_type 1 element []
> recurse
node_name #text node_type 3 text [01 October 2007]
no_attr
< recurse
node_name articles node_type 1 element []
> recurse
node_name article node_type 1 element
attr_cnt=3 [ id= 063 title= Ajax Tutorial date= 1/oct/2007]
node_name article node_type 1 element
attr_cnt=3 [ id= 062 title= BlackfishSql date= 24/sep/2007]
node_name article node_type 1 element
attr_cnt=3 [ id= 061 title= Dbx4 Programming date= 19/sep/2007]
< recurse
< recurse
< recurse
< recurse
< on_readystate_change
|
Using this knowledge, we can now fill a TEXTAREA with the .XML values:
function analyze_xml(p_c_xml_root_node)
{
var l_result_display= 'last updated : \n ';
l_c_updated_list =
p_c_xml_root_node.getelementsbytagname('updated');
l_result_display += l_c_updated_node.firstchild.data + '\n ';
l_c_article_list = p_c_xml_root_node.getelementsbytagname('article');
l_article_count= l_c_article_list.length;
for (var l_index= 0; l_index< l_article_count; l_index ++ )
{
l_c_article_node= l_c_article_list[l_index];
l_article = '';
for (var l_attribute= 0;
l_attribute< l_c_article_node.attributes.length;
l_attribute ++)
l_article += l_c_article_node.attributes[l_attribute].nodevalue+ ' ';
l_result_display += l_article+ '\n';
};
l_memo_ref= window.document.display_form.display_memo;
l_memo_ref.value = l_result_display;
} // analyze_xml
| and getting the page in Internet Explorer: 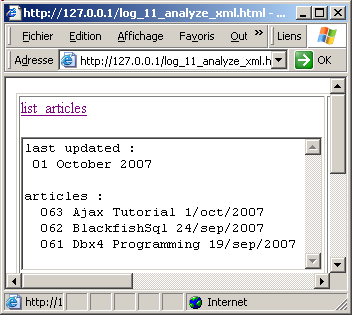
2.6.2 - Sending Parameters to the Server We started to explain that JavaScript was about requesting data pieces from the Server. In the previous examples, we received ALL the Server data.
In order to be able to paginate thru the data, our request has to send, as parameters, the start value and the count, and to manage the current starting point at the Client. Using JavaScript
- we can save in a variable the current starting row
- when we request the next page, we have to send the next starting row and the requested count as parameters in the URL
- the Server on the other side will extract those parameters, and build an .XML response taylored to those parameters.
Sending parameters from JavaScript is performed by appending the parameter key
and value after the requested page: - ? and the key=value for the first parameter
- & and the key=value for the next parameter
For instance, to request 4 articles starting at 16 we could write
GET /article_list.xml?row_start=16&row_count=4 HTTP/1.1 |
In order to implement this
- for the .HTML page
- our JavaScript declares 2 global variables, g_start_row, and g_row_count
- our main "article_list" link will call a function which fetches the first row packet
- we added a "Next" link on the .HTML page which increments the
- this link increments the g_start_row, and grabs the next row packet
- on the Server
- we check for the presence of parameters. If this is the case, we extract the parameter values using RequestInfo.Params.Values:
var my_start_row, my_row_count: Integer;
with RequestInfo.Params do
begin
my_start_row:= StrToInt(Values['start_row']);
my_row_count:= StrToInt(Values['row_count']);
end; // with RequestInfo.Params
| - we load from an .TXT file the article list in a tStringList, and use
this list to add the requested articles to the response
In more detail: - in the .HTML, we implement paging:
<HTML>
<HEAD>
|
<SCRIPT>
function load_xml(p_xml_file_name)
{
var l_c_xml_http_request;
function create_xml_http_request()
{
if (window.XMLHttpRequest)
{
l_c_xml_http_request = new XMLHttpRequest();
}
else
if (window.ActiveXObject)
{
l_c_xml_http_request = new ActiveXObject("Microsoft.XMLHTTP");
}
if (l_c_xml_http_request == null)
alert("does not support xml_http_request");
} // create_xml_http_request
function get_and_parse_xml()
{
// -- set the handler
l_c_xml_http_request.onreadystatechange = on_readystate_change;
// -- request the file by sending a GET
l_c_xml_http_request.open("GET", p_xml_file_name, true);
// -- acknowledge end
l_c_xml_http_request.send(null);
} // get_and_parse_xml
function on_readystate_change()
// -- called once the .XML has been received
{
if (l_c_xml_http_request.readyState == 4)
{
if (l_c_xml_http_request.status != 200)
alert('error loading HML file. Status: '
+ l_c_xml_http_request.status + ' '
+ l_c_xml_http_request.statusText);
analyze_xml(l_c_xml_http_request.responseXml);
}
else
{
// alert('error readystate '+ l_c_xml_http_request.readyState);
}
} // on_readystate_change
function analyze_xml(p_c_xml_root_node)
{
var l_result_display= 'last updated : \n ';
l_c_updated_list = p_c_xml_root_node.getElementsByTagName('updated');
l_c_updated_node= l_c_updated_list[0];
l_result_display += l_c_updated_node.firstChild.data + '\n ';
l_c_article_list = p_c_xml_root_node.getElementsByTagName('article');
l_article_count= l_c_article_list.length;
for (var l_index= 0; l_index< l_article_count; l_index ++ )
{
l_c_article_node= l_c_article_list[l_index];
l_article = '';
for (var l_attribute= 0;
l_attribute< l_c_article_node.attributes.length;
l_attribute ++)
l_article += l_c_article_node.attributes[l_attribute].nodeValue+ ' ';
l_result_display += l_article+ '\n';
};
l_memo_ref= window.document.display_form.display_memo;
l_memo_ref.value = l_result_display;
} // analyze_xml
create_xml_http_request();
get_and_parse_xml();
} // load_xml
var g_start_row= 0;
var g_row_count= 3;
var g_xml_page_name;
function get_next_article_page(p_xml_page_name)
{
g_xml_page_name= p_xml_page_name;
l_request= p_xml_page_name
+ '?start_row='+ g_start_row
+ '&row_count='+ g_row_count ;
load_xml(l_request);
} // get_next_article_page
function get_next_page()
{
g_start_row += g_row_count;
get_next_article_page(g_xml_page_name);
} // get_next_page
</SCRIPT>
| </HEAD>
<BODY>
<DIV>
<A href="#" onClick="get_next_article_page('/article_list.xml');">
article_list</A><BR>
</DIV>
<DIV>
<FORM name="display_form">
<TEXTAREA name="display_memo" rows=10 cols=10></TEXTAREA>
</FORM>
</DIV>
<DIV>
<A href="#" onClick="get_next_page();">next</A><BR>
</DIV>
</BODY>
</HTML>
|
|
- in the Indy Server:
procedure TForm1.IdHTTPServer1CommandGet(AThread: TIdPeerThread;
RequestInfo: TIdHTTPRequestInfo; ResponseInfo: TIdHTTPResponseInfo);
function f_build_static_response(p_requested_document: String): String;
begin
// -- ...ooo... as before
end; // f_build_static_response
function f_xml_response(p_request_command: String;
p_c_request_params: tStrings): String;
procedure build_response;
begin
with tStringList.Create do
begin
Add('<xml>');
Add(' <updated>01 October 2007</updated>');
Add(' <articles>');
Add(' <article id="063" title="Ajax Tutorial" date="1/oct/2007" />');
Add(' <article id="062" title="BlackfishSql" date="24/sep/2007" />');
Add(' <article id="061" title="Dbx4 Programming" date="19/sep/2007" />');
Add(' </articles>');
Add('</xml>');
Result:= Text;
end; // with tStringList.Create
end; // build_response
procedure build_parametrized_response;
var l_start_row, l_row_count: Integer;
l_c_article_parameter_list: tStringList;
l_row_index: Integer;
begin
with RequestInfo.Params do
begin
l_start_row:= StrToInt(Values['start_row']);
l_row_count:= StrToInt(Values['row_count']);
end; // with RequestInfo.Params
l_c_article_parameter_list:= tStringList.Create;
l_c_article_parameter_list.LoadFromFile(f_exe_path+ k_article_parameter_file_name);
with tStringList.Create do
begin
Add('<xml>');
Add(' <updated>01 October 2007</updated>');
Add(' <articles>');
for l_row_index:= l_start_row to l_start_row+ l_row_count- 1 do
Add(' <article '+ l_c_article_parameter_list[l_row_index]+ ' />');
Add(' </articles>');
Add('</xml>');
Result:= Text;
Free;
end; // with tStringList.Create
l_c_article_parameter_list.Free;
end; // build_parametrized_response
begin // f_xml_response
if RequestInfo.Params.Count> 0
then build_parametrized_response
else build_response;
end; // f_xml_response
var l_requested_document: String;
l_extension: String;
begin // IdHTTPServer1CommandGet
// -- requested document
l_requested_document:= RequestInfo.Document;
// -- build the content: either initial static page,
// -- or dynamic .XML data
if f_start_is_equal_to(l_requested_document, '/article_list.xml')
then begin
// -- must be present or will not see .XML
ResponseInfo.ContentType:= 'text/xml';
ResponseInfo.ContentText:=
f_xml_response(l_requested_document, RequestInfo.Params);
end
else begin
// -- build 'Content-Type header"
l_extension:= ExtractFileExt(l_requested_document);
if l_extension= '.css'
then ResponseInfo.ContentType:= 'text/css'
else
if l_extension= '.js'
then ResponseInfo.ContentType:= 'text/javascript'
else ResponseInfo.ContentType:= 'text/html';
ResponseInfo.ContentText:=
f_build_static_response(l_requested_document);
end;
end;
end; // IdHTTPServer1CommandGet
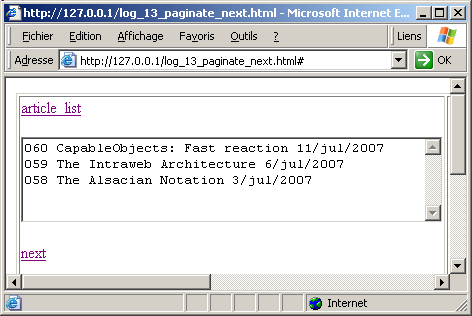
| - the snapshot of clicking "article_list" and "next":
Note that - we only adde "next". Obviously "previous", or "first", "last" or entering
the row count in a input box could be easily added
- we also could have built (statically or using JavaScript) a nice grid (using <TABLE>) and even with a nice row header
2.6.3 - .XML selective data extraction So far we have hardcoded the .XML data extraction. We could use a more flexible tool by writing a generic .XML analysis tool First, we create a call back mechanism:
- the XML DOM analyzer built a tree in memory
- we walk this tree in the usual to-down, left-right way
- if the XML tag name belongs to some predefined names, we call the corresponding handling event
Here is the recursive analyzer:
// -- recurse on tree and use callbacks
var g_on_enter_tag_callback_array = new array();
var g_on_exit_tag_callback_array = new array();
function add_callback(p_key_name, p_entry_callback, p_exit_callback)
// -- todo rename add_tag_callback
// -- add a tag event. The p_key_name should be the name of an XML tag <company ...
{
do_display("> add_callback "+ p_key_name);
// -- add this entry to the array
g_on_enter_tag_callback_array[p_key_name] = p_entry_callback;
g_on_exit_tag_callback_array[p_key_name] = p_exit_callback;
do_display("< add_callback");
} // add_callback
function remove_callback(p_key_name)
{
g_on_enter_tag_callback_array[p_key_name] = 0;
g_on_exit_tag_callback_array[p_key_name] = 0;
} // remove_callback
function analyze_xml_node_recursive(p_c_xml_node)
// -- parameter: root
// -- or parent_node.firstChild
{
while(p_c_xml_node)
{
// -- call PRE event
l_callback= g_on_enter_tag_callback_array[p_c_xml_node.nodename];
if ( l_callback )
l_callback(p_c_xml_node);
// -- recurse down
analyze_xml_node_recursive(p_c_xml_node.firstchild);
// -- call POST event
l_callback= g_on_exit_tag_callback_array[p_c_xml_node.nodename];
if(l_callback)
l_callback(p_c_xml_node);
// -- get the next sibbling
p_c_xml_node = p_c_xml_node.nextsibling;
};
} // analyze_xml_node_recursive
| and our main .XML load and analysis script becomes:
function load_xml(p_xml_file_name)
{
var l_c_xml_http_request;
function create_xml_http_request()
{
if (window.xmlhttprequest)
{
l_c_xml_http_request = new xmlhttprequest();
}
else
if (window.activexobject)
{
// IE/Windows ActiveX version
l_c_xml_http_request =
new activexobject("Microsoft.XMLHTTP");
}
if (l_c_xml_http_request == null)
alert("does not support xml_http_request");
} // create_xml_http_request
function get_and_parse_xml()
{
// -- set the handler
l_c_xml_http_request.onreadystatechange = on_readystate_change;
// -- request the file by sending a GET
l_c_xml_http_request.open("GET", p_xml_file_name, true);
// -- acknowledge end
l_c_xml_http_request.send(null);
} // get_and_parse_xml
var g_result_display;
function on_readystate_change()
// -- called once the .XML has been received
{
if (l_c_xml_http_request.readystate == 4)
{
if (l_c_xml_http_request.status != 200)
alert('error loading HML file. Status: '
+ l_c_xml_http_request.status + ' '
+ l_c_xml_http_request.statustext);
var l_c_xml_response = l_c_xml_http_request.responsexml;
// -- initialize the callback
add_callback('article', generate_article_callback, 0);
g_result_display = '';
analyze_xml_node_recursive(l_c_xml_response);
l_memo_ref= window.document.display_form.display_memo;
l_memo_ref.value = g_result_display;
}
else
{
do_display("processing: readyState "
+ l_c_xml_http_request.readystate+ '...');
}
} // on_readystate_change
function generate_article_callback(p_c_article_node)
// -- called for each <ARTICLE> node
{
l_c_attribute_list= p_c_article_node.attributes;
if (l_c_attribute_list)
{
l_attribute_count= l_c_attribute_list.length;
if ( l_attribute_count )
{
l_article = '';
for (var l_attribute = 0;
l_attribute< l_attribute_count;
l_attribute ++ )
{
l_c_attribute_node= l_c_attribute_list[l_attribute];
l_article += l_c_attribute_node.nodevalue+ ' ';
}; // for l_index
}; // has attributes
else l_article = '';
g_result_display += l_article+ '\n';
do_display(g_result_display);
}
else display('no_attributes');
} // generate_article_callback
create_xml_http_request();
get_and_parse_xml();
} // load_xml
|
Please note that
- in this example we displayed all the attributes, but we could have filtered some fields using tests on the attribute value, or the my_c_node.getAttribute(my_key) function
Here is a snapshot with all the articles, and indented after each row, the "date" and "title" extracted with
l_article += '\n'
+ ' ['+ p_c_article_node.getattribute('date')+ '] '
+ p_c_article_node.getattribute('title');
| with the following result:
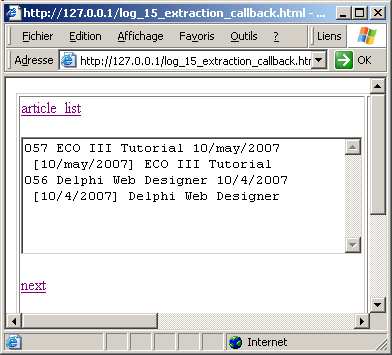 - we only added one callback. But we could have added other callbacks, like a callback on the "updated" tag
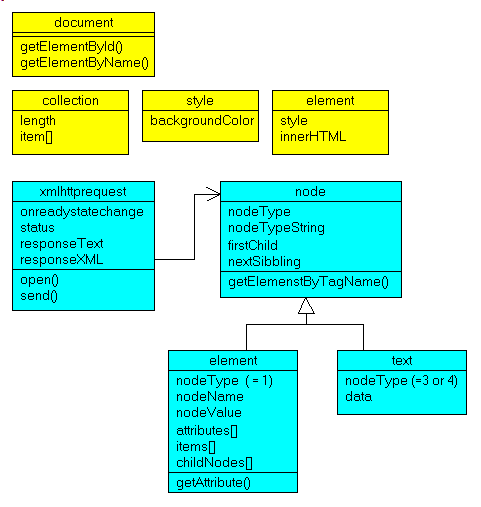
2.6.4 - JavaScript and DOM objects Here is the diagram of the different JavaScript objects we used in this paper:
2.7 - Javascript Development Tool 2.7.1 - Debugging JavaScript We have used the Indy tIdHttpServer to be able to debug our AJAX Javascript example.
This was not so easy, because JavaScript is quite brittle, as seen by a Pascal developer. Here are just a few among the many bugs we encountered: - from JavaScript:
- omission of VAR in FOR index
- wrong casing, like NodeValue instead of nodeValue
- many missing string ending quotes
- the mysterious ending ";" rule
- some difficulties in selecting between Value, nodeValue or Data
- the usual C mistakes of a hard dyed Pascal programmer : "=" instead of "=="
- a fundamental logical bug: we wanted to initialize the display and present
it before and after calling get_and_parse_xml(). This does not work, since the loading is an ASYNCHRONOUS call: the control returns instantaneously after the call, and any processing performed after the call is not
guaranteed to work on the received answer. The event on_readystate_change was precisely created to cope with this decoupling: when the state is 4, we know that the response has been received
- on the Server side, we also had mistakes, like a mission </articles> tag for instance
2.7.2 - The JavaScript Log The most useful tool is our JavaScript log, which enabled us to display
indented messages in a TEXTAREA. Here is the minimal version of this logging tool:
<HTML>
<HEAD>
|
<SCRIPT language="JavaScript">
var g_indentation=0;
function do_display(p_string)
{
var spaces="";
if (p_string.substring(0, 1)=="<")
{
g_indentation-= 2;
}
for (l_index=0; l_index< g_indentation; l_index++)
{
spaces+= " ";
}
l_memo_ref= window.document.debug_form.debug_memo;
l_memo_ref.value += spaces+ p_string + "\n";
l_memo_ref.scrollTop = l_memo_ref.scrollHeight;
if (p_string.substring(0, 1)==">")
{
g_indentation+= 2;
}
} // do_display
function do_clear_display()
{
window.document.debug_form.debug_memo.value= "";
} // do_clear_display
</SCRIPT>
|
</HEAD>
<BODY>
<TABLE border= 1 width=100%><TBODY><TR>
<TD width=40% valign=top>
<A href="#" onClick="do_display('Hello'); return false;">test</A>
</TD>
<TD valign=top>
<!-- debug display -->
<TABLE border= 0><TBODY>
<TR><TD>
<FORM name="debug_form">
<TEXTAREA name="debug_memo" rows=10 cols=40></TEXTAREA>
</FORM>
</TR></TD>
</TR></TBODY></TABLE>
</TD>
</TR></TBODY></TABLE>
</BODY>
</HTML>
|
|
And here is a snapshot of the log in tWebBrowser: 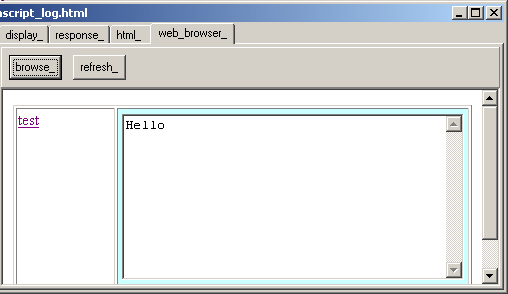
If you do not want to use the logging facility, simply write an empty do_display() routine, or, more radical, remove all calls to do_display()
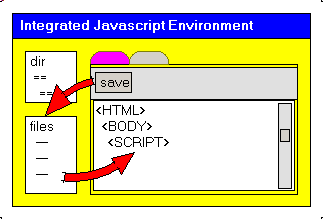
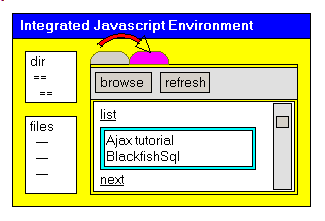
2.7.3 - An integrated environment
In order to develop Ajax projects, we need 3 tools - Delphi to create the Web Server using the Indy .HTTP Server
- NotePad to write the .HTML page and the JavaScript scripts
- Internet Explorer to get the initial page, and paginate thru the .XML data, which is the fundamental purpose of AJAX
To avoid shifting from one tool to the other, and more importantly to
synchronyze the pathes used to save the different projects, we decided to integrate the three tools: - first added the possibility to edit the .HTML page from within our
application. We simply load the .HTML in a tMemo, and save the resulting text into the .HTML file. And we have thrown in an "history" copy before overwriting the .HTML with its new version
- to alleviate the burden of starting the IE Browser, we first added a
button which copied the correct URL in the Clipboard. It worked. However, sadly enough, mistakes still were not reported by IE. The page stayed blank with no message whatsoever.
So we integrated a tWebBrowser in the application, which allows to display the .HTML page, and to click on the links. It was some surprise to find out that the embedded tWebBrowser did flag the mistakes, being so kind as to
sometimes give us a hint like "object xxx unknown", "this object does not handle method mm" or "zzz requires an object". There MUST be a way to get the same messages from the standalone Internet Explorer, but since our
embedded tWebBrowser worked, we did not investigate it any more. - here is a snapshot of the .ZIP version with the last example:
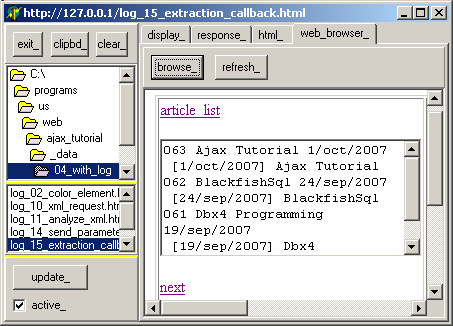
The attached .ZIP source code contains a Delphi project with
- a DirectoryListBox and FileListBox, allowing us to load different .HTML files
- the chosen .HTML is loaded in a Memo, which has elementary search capability. Of course the text can be saved back on disk with the same name
or another name
- when we are satisfied with the .HTML, we can start the WebBrowser (start the first time, refresh after this). We even can start this by using F9 from the tMemo !
3 - AJAX in perspective 3.1 - Internet Express Delphi was ahead of its time. Since Delphi 6, or even sooner, we had the
Internet Express code as an Internet example. We have long ignored this, since we did not want to touch JavaScript, even with a ten-foot pole. When we tried to do some web accounting package, we
looked more deeply at it, but did not fully grasp the intent and benefits of this framework. Well, is is AJAX long before this term was coined.
3.2 - AJAX Libraries
Since the AJAX technique was around since many year, why the recent success ? Any tutorial will mention GoogleMaps and Google Gmail. We used here some kind of "homegrown AJAX". But for industrial use, we would
search for some libraries, which make the exchange between the Browser and the Server more easy. There are many such libraries, even in source code, that you can find using Google. With Delphi, we already have two libraries:
- for Win32, Intraweb (VCL for the Web as is is now called) offers such a library
- for .Net, the new RAD Studio 2007 allows us to use the Asp.Net 2.0 AJAX library (ATLAS)
4 - Download the Sources Here are the source code files: - ajax_tutorial.zip: the integrated FileListBox loader, .Html memo
editor, Http Server, and WebBrowser (32 K)
- ajax_html_demos.zip: the .HTML used in this AJAX tutorial (3 K):
- javascript_log.html : our indented JavaScript log
- js_01_color_red.html : OnClick event
- js_02_color_element.html : referencing a tag ID
- js_03_inner_html.html : replacing the content of a tag
- log_10_xml_request.html : fetching some .XML content from the Server
- log_11_analyze_xml.html : extracting the .XML text and attribute values
- log_14_send_parameters_paginate.html : sending parameters to the Server to paginate thru the data
- log_15_extraction_callback.html : using callbacks to automate tag extraction
The .ZIP file(s) contain: - the main program (.DPR, .DOF, .RES), the main form (.PAS, .DFM), and any other auxiliary form
- any .TXT for parameters, samples, test data
- all units (.PAS) for units
Those .ZIP - are self-contained: you will not need any other product (unless expressly mentioned).
- for Delphi 6 projects, can be used from any folder (the pathes are RELATIVE)
- will not modify your PC in any way beyond the path where you placed the .ZIP (no registry changes, no path creation etc).
To use the .ZIP:
- create or select any folder of your choice
- unzip the downloaded file
- using Delphi, compile and execute
To remove the .ZIP simply delete the folder.
The Pascal code uses the Alsacian notation, which prefixes identifier by program area: K_onstant, T_ype, G_lobal, L_ocal, P_arametre, F_unction, C_lass etc. This notation is presented in the Alsacian Notation paper.
As usual:
- please tell us at fcolibri@felix-colibri.com if you found some errors, mistakes, bugs, broken links or had some problem downloading the file. Resulting corrections will
be helpful for other readers
- we welcome any comment, criticism, enhancement, other sources or reference suggestion. Just send an e-mail to fcolibri@felix-colibri.com.
- or more simply, enter your (anonymous or with your e-mail if you want an answer) comments below and clic the "send" button
- and if you liked this article, talk about this site to your fellow developpers, add a link to your links page ou mention our articles in your blog or newsgroup posts when relevant. That's the way we operate:
the more traffic and Google references we get, the more articles we will write.
5 - See Also Of interest to readers of this article might be:
- The TCP/IP Sniffer which was used to monitor the packet exchanges between the Http Server and the (standalone) Internet
Explorer. Indy does have properties to get the full Headers, but this is not as complete as using a bona fide TCP/IP sniffer
- the papers used our last published papers as the database example. And in
this paper list is an article about programming the brand new BlackfichSql standalond database of RAD Studio 2007.
Well it turns out that we could have placed the article list in a database managed by Blackfish Sql
- we also organize frequent Web Programming trainings
(Socket programming, Asp.Net 1.0 and Asp.Net 2.0 with Delphi, Intraweb programming)
6 - The author Felix John COLIBRI works at the Pascal
Institute. Starting with Pascal in 1979, he then became involved with Object Oriented Programming, Delphi, Sql, Tcp/Ip, Html, UML. Currently, he is mainly
active in the area of custom software development (new projects, maintenance, audits, BDE migration, Delphi
Xe_n migrations, refactoring), Delphi Consulting and Delph
training. His web site features tutorials, technical papers about programming with full downloadable source code, and the description and calendar of forthcoming Delphi, FireBird, Tcp/IP, Web Services, OOP / UML, Design Patterns, Unit Testing training sessions.
|