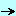|
FelSpider: Web Spider - Felix John COLIBRI. |
- abstract : Download a complete web site, with custom or gui filtering and selection of the downloaded files.
- key words : web spider, downloader, off line reader, HTTP, HTML, TCP IP, virtual path
- software used : Windows XP, Delphi 6
- hardware used : Pentium 1.400Mhz, 256 M memory, 140 G hard disc
- scope : Delphi 1 to 8 for Windows, Kylix
- level : Delphi developer
- plan :
1 - Introduction Whenever I am hitting an interesting Web site, I am always afraid to miss some
important information which might be relocated elsewhere, or altogether vanish. With todays disk capacity, it is easy to save those pages on a local drive, possibly adding some indexing scheme or local search engine.
To automate the download of the pages from a site, we use a Web Spider. The basic idea is very old: start with some .HTML page, extract all its links, and recurse by downloading those links.
We already presented a single page downloader, which downloads a page, analyzes the anchor tags, and downloads the corresponding
image tags. So all the features are already present. The spider then only adds the page selection.
2 - Web Spidering 2.1 - The objective
Knowing how to download a page and collect all the anchor tags from an .HTML page and recursively perform the same task, why can't we simply download all the files, and read the whole thing off-line ?
The answer is simple: file swamping. If you donwload, say, the page from a learned teacher at MIT or Waterloo about "UML and Design Patterns", chances are that this page will also reference:
- other courses taught by the same professor which might not interest you (java programming, computer 101 etc)
- coleague's and budies pages, which might work in other areas (chemistry or psychiatry)
- personal pages (resume, photo galleries of last conventions, favorite songs)
- links to other universities with similar courses. And from there, the flood starts anew.
So some rules must be applied to constrain this flood of pages.
2.2 - Spidering Strategies Irrespective of the technique used to filter out downloaded pages, here are a couple of target pages: - we can forbid some pages that we know will seldom interest us. In our case,
all multi-media stuff is banned right from the start: no .AVI, .MOV, .WAV and the like. Note that since the advent of BDN (Borland community movies) this might change.
- the second most effective technique was to limit the pages to the request's local path. If we request Bertrand MEYER's page:
http://www.inf.ethz.ch/personal/meyer/ | we are usually also interested to load the sub directories referenced in this page:
http://www.inf.ethz.ch/personal/meyer/events/2001/ubs.html
http://www.inf.ethz.ch/personal/meyer/events/talks.html
http://www.inf.ethz.ch/personal/meyer/images/sounds/pronunciation.html
http://www.inf.ethz.ch/personal/meyer/publications/
http://www.inf.ethz.ch/personal/meyer/publications/computer/dotnet.pdf
http://www.inf.ethz.ch/personal/meyer/publications/inaugural/inaugural.pdf
http://www.inf.ethz.ch/personal/meyer/publications/joop/overloading.pdf
http://www.inf.ethz.ch/personal/meyer/publications/online/bits/index.html |
but would be reluctant to download pages with a complete different domain:
http://www.csse.monash.edu.au
http://se.inf.ethz.ch/jobs/ | Some references should interest us (page aliases or pages with quite similar content):
http://www.inf.ethz.ch/~meyer/
http://www.inf.ethz.ch/~meyer/events/
http://www.inf.ethz.ch/~meyer/ongoing/
http://www.inf.ethz.ch/~meyer/ongoing/covariance/recast.pdf
http://www.inf.ethz.ch/~meyer/ongoing/etl/
http://www.inf.ethz.ch/~meyer/ongoing/etl/agent.pdf
http://www.inf.ethz.ch/~meyer/ongoing/references/
http://www.inf.ethz.ch/~meyer/publications/
http://www.inf.ethz.ch/~meyer/publications/events/events.pdf
http://www.inf.ethz.ch/~meyer/publications/extraction/extraction.pdf
http://www.inf.ethz.ch/~meyer/publications/ieee/trusted-icse.pdf
http://www.inf.ethz.ch/~meyer/publications/proofs/references-proofs.pdf
http://www.inf.ethz.ch/~meyer/publications/reviews/csharp-review.html | and some could interest us (his books, I guess):
http://www.inf.ethz.ch/
http://vig.pearsoned.com/store/product/1,3498,store-562_isbn-0130622966,00.html
http://www.amazon.com/exec/obidos/ASIN/0130331155/qid=1003330798/sr=8-1/ref=sr_8_7_1/104-4 | Based on this example, we see that: - pages in sub directories are very often of interest
- pages in parent directories are of increasing generality, and the risk of overflooding increases
- pages in other domain cannot easily be automatically selected, even if they have a close relation to the requested domain
- some site offer links to files available for download. We frequently encountered this for "reading lists" of some university courses. Some teachers place those files in a local (sometimes private) directory, but
some other simply list the URL where a copy of the file is available. So, in this case, the strategy should be "download all the non-html files listed in this page". Access to those domains should be allowed, but parsing of the
corresponding parent page and pathes refused.
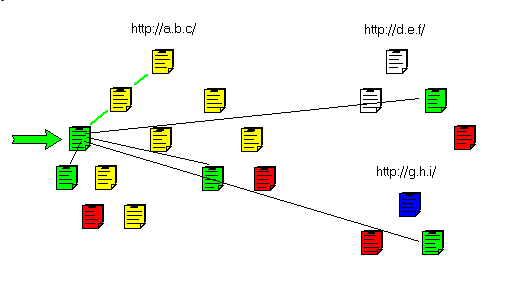
Here is an example with three different sites: - the three sites
- we forbid some pages (.AVI, .MOV, .DOC etc)
- here is an example of page and sub pathes:
- here is an example of page+ any pages of some kind (reading list .PDF):
2.3 - File organization When saving the downloaded pages on disc, we can adopt an organization - by topic (database, web programming, accounting ...)
- by request domain and path name (c:\www.cs.berkeley.edu\...,
c:\www.ece.uwaterloo.ca\... etc)
When the dowloaded volume increases, the second option seems the best, since it avoids many of the aliasing problems. We cannot save the files under the requested page name only, since a page often
contains links to some parent page (for an organization logo, for instance). And even if we adopt a strict "only sub directory" structure, we might want to later download sibbling directories, or upper directories. Here is an example: Of course, finding the page with Windows File Explorer will be more difficult, since some content will be nested at deeper levels. But this is why we did
build the a file search engine ("find in file") with some expression power. We could then ask all files satisfying:
ModelMaker OR (Delphi AND UML) OR ("class diagrams" AND NOT java) |
We also include an "__doc.txt" file at the root of all our downloade sites (in our case, this would be c:\www.modelmakertools.com\__doc.txt), and we usually place some key words in this text. All the __doc.txt can then be automatically
parsed for some expressions to tell which sites contain some topic.
Note that our naming scheme is not totally alias free. Some sites can be renamed, split or otherwise reorganized under different names. This is even the
case for our own site, which can be reached with www.felix-colibri.com OR www.colibrix.com. Removing such alias would need the computation of unique signature for each page and an indexing scheme. We considered that it would
require too much work to simply remove some redundancy.
2.4 - The Spidering algorithm Here is the pseudo code of our spider:
fill the requested URL list
selectect the first URL
REPEAT
donwload the selected URL
save the page
IF this is an HTML containing page
THEN
extract the anchor tags
filter the tags
select the next URL
UNTIL no more URLs
| and:
- "fill the requested URL list": we usually start with a seed page. However we could type a list of URLs in a tMemo, load the list from a "todo" file, or paste some URLs from previously rejected pages
- "select the first URL" : this starting page is either an URL ending with .HTML, .PHP, .ASP etc, or the domain name, or some path in the target domain.
http://download.oracle.com/otn/nt/oracle10g/10g_win32_db.zip
/downloads/index.html
/ww/
aboutMe.html#contactInfo
bliki
../../super_search.htm
./files/tables.zip
http://cc.borland.com/beta/Item.aspx?id=23191 | - "donwload the selected URL" : the socket sends a GET, and the Server answers either with the requested explicit page, or with a default page
(index.html), or the page dynamically build from a CGI request. The socket the receives the HTTP answer
- "save the page" : in the usual "domain download" case, we save the page in
the path derived from the URL. In the case of a "reading list" download, we save the files in the requested page folder. And if the name of a file is a relative name, we must add the absolute path.
- "IF this is an HTML containing page" : we cannot use the request extension as a reliable way to trigger the .HTML parsing.
So, when the extension is not an .HTML like exention or an explicit non-HTML
exention (.ZIP, .PDF, .PNG ...), we look whether the file contain some .HTML tag. We chose <HTML> and </HTML> as the test criterion, although this is not bullet proof:
- some binary file might contain those tags, and still conaint only binary data
- some web pages do not contain <HTML> and </HTML> (only <BODY>, or even only the text with some text tags and some anchors
- "extract the anchor tags" if the page is a declared or detected .HTML page, we parse the content and build the anchor tag list
- "filter the tags" : this is the filtering stage. Here we can
- eliminate unwanted extensions (.WAV ...)
- eliminate some links based on textual patterns (no URL containing "resume", or "photo gallery" etc
- eliminate links which do not contain the same domain as the initially requested page
- "select the next URL" : this step will determine the dowload order. If we download all files up to the end, the download order has no importance whatsoever. But if we might abort the process after some time (bug,
overflooding, timeout ...), then it is obviously better to first download the "best" pages. The ranking function obviously depends on the user needs. In our case
- we usually first donwload the non-HTML files (the .PDD, .ZIP etc)
- then we donwload the .HTML pages
- first the sub pages
- then the parent pages, gradually moving from the current path to the site root
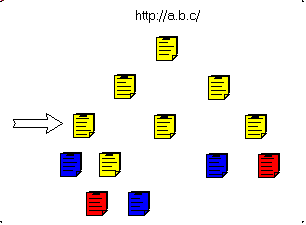
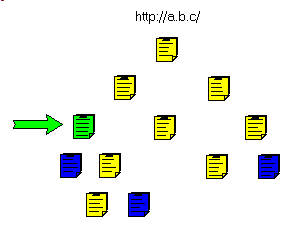
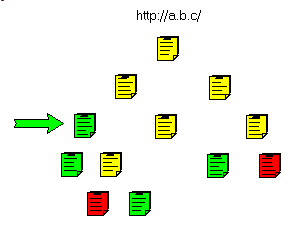
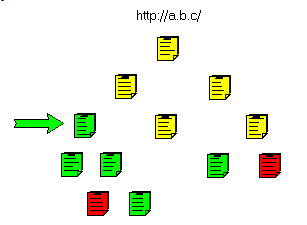
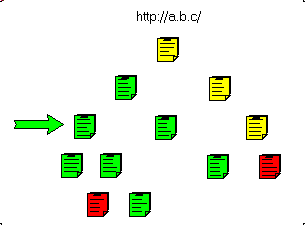
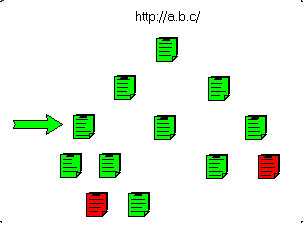
This can be presented in the following figure.
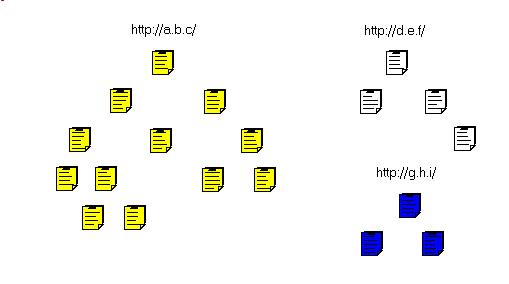
- In Red the unwanted pages (.MOV) and in blue the non-HTML pages (.PDF):
- we download the target page:
- then the non HTML pages:
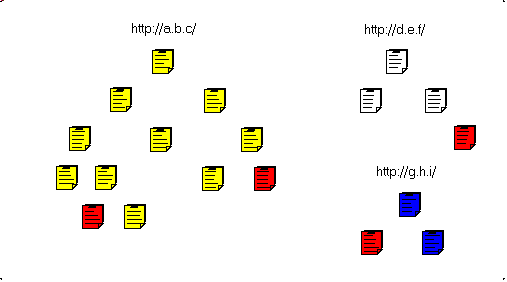
- and the sub pages:
- and we gradually fetch the parent pages:
and
So we fixed the broad lines (first the non-HTML, then the sub pages, then the parent pages), and you still have full source code to change this. To add some more flexibility, we added two hooks:
- a customizable filtering callback where one can add some condition to remove some pages
- a customizable next page selection procedure
We also added very limited GUI selection with checkboxes. The user can select:
- the page level (parent, the page itself, child pages)
- the type of pages (none, all, only .HTML-like, image, zip and .PDF like)
3 - The Delphi full Source code
3.1 - The Overall organization The spider is directly derived from the downloader. The structure and operation of the downloader has been presented in the Web Downloader paper at great length.
The spider only introduces filtering and page ordering functionalities. So we simply derived the c_site_spider from the c_spider, adding the needed attributes and methods. The main form was also slightly changed.
The filtering and selection additions are: - a default management
- a custom callback possibility (with some requested coding on the main Form)
- a gui handling
3.2 - The Guid management
The main Form presents 3 levels of buttons allowing the user to decide what to download: 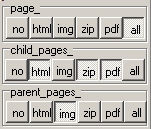 The snapshot shows the selection of
- all pages at the requested URL level
- the .HTML, .ZIP and .PDF from the children
- only the images from the parent pages
Here are the definitions for this user level management:
t_page_level_type= (e_unknown_level, e_outside_level, e_parent_level,
e_page_level, e_child_level);
t_page_type= (e_unknown_type, e_no_type, e_html_type, e_image_type,
e_zip_type, e_pdf_type, e_all_type);
t_page_selection= array[e_unknown_level..e_child_level, e_unknown_type..e_all_type] of Boolean;
t_fo_check_url= function(p_c_url: c_url): Boolean of Object;
t_fn_check_url= function(p_c_url: c_url): Boolean;
c_site_spider=
class(c_spider)
m_selection_array: t_page_selection;
m_page_level_fo_array: array[e_parent_level..e_child_level] of t_fo_check_url;
m_page_type_fn_array: array[e_no_type..e_all_type] of t_fn_check_url;
Constructor create_site_spider(p_name, p_root_save_path: String; p_c_url: c_url);
procedure append_selection_procedure(p_po_on_select_url: t_po_accept_url);
procedure set_selection(p_page_level_type: t_page_level_type;
p_page_type: t_page_type; p_set: Boolean);
procedure display_selection;
function f_has_gui_selection: Boolean;
procedure filter_other_pages; Override;
function f_c_select_next_page: c_remote_file; Override;
end; // c_site_spider
| and: - we use two enumerated types for our levels and page types
- the c_site_spider contains the m_selection_array where the boolean are stored by the user
- the setting of the booleans is performed using the set_selection method
The user then checks some options (which levels, which pages), and when we creat the c_site_spider, we check those buttons:
procedure TForm1.goClick(Sender: TObject);
procedure add_gui_selection;
begin
with g_c_spider do
begin
set_selection(e_parent_level, e_no_type, no_parent_.Down);
set_selection(e_parent_level, e_html_type, html_parent_.Down);
set_selection(e_parent_level, e_image_type, image_parent_.Down);
// ...
|
To select which pages must be kept for download, we test each anchor tag:
procedure c_site_spider.filter_other_pages;
// -- remove unwanted pages
procedure filter_gui_choices;
function f_accept(p_c_url: c_url): Boolean;
var l_page_level_type: t_page_level_type;
l_page_type: t_page_type;
begin
Result:= True;
for l_page_level_type:= e_parent_level to e_child_level do
for l_page_type:= e_no_type to e_all_type do
if m_selection_array[l_page_level_type, l_page_type]
and m_page_level_fo_array[l_page_level_type](p_c_url)
then
case l_page_type of
e_no_type : Result:= False;
e_all_type : Result:= True;
else Result:= m_page_type_fn_array[l_page_type](p_c_url);
end; // case
end; // f_accept
var l_remote_file_index: Integer;
begin // filter_gui_choices
with m_c_remote_file_list do
for l_remote_file_index:= 0 to f_remote_file_count- 1 do
with f_c_remote_file(l_remote_file_index) do
if not m_downloaded and m_do_download
then m_do_download:= f_accept(m_c_normalized_url);
end; // filter_gui_choices
begin // filter_other_pages
// -- first remove GUI choices
if f_has_gui_selection
then filter_gui_choices
else
// ...
end; // filter_other_pages
| where
The selection of the next page to download is performed in the f_c_select_next_page function.
3.3 - The Custom Filtering and Selection
We also added the possibility to let the Delphi developper write his own custom filtering and selection methods.
For the filtering, we simply created a callback in the c_site_spider CLASS,
and if this method is initialized by the developer, the filtering procedure uses this callback to decide if a pages should be kept or not: - here is the filtering hook:
t_po_accept_url= procedure(p_c_url: c_url; var pv_accept: Boolean) of Object;
c_site_spider= class(c_spider)
m_on_filter_url: t_po_accept_url;
// ...
end; // c_site_spider
|
- the developper adds the method in tForm1 CLASS:
TForm1= class(TForm)
// ...
private
procedure filter_page(p_c_url: c_url; var pv_accept: Boolean);
end; // tForm1
| - with, for instance, this check:
procedure TForm1.filter_page(p_c_url: c_url; var pv_accept: Boolean);
begin
with g_c_spider do
pv_accept:=
(
f_is_child_page(p_c_url)
and
f_is_html_extension(p_c_url)
)
or
(
f_is_domain_page(p_c_url)
and
not f_is_child_page(p_c_url)
and
(p_c_url.m_extension= '.png')
);
end; // filter_page
|
- and the callback pointer is initialized when the c_site_spider object is created:
c_site_spider= class(c_spider)
m_oa_on_select_url: array of t_po_accept_url;
// -- ...
end; // c_site_spider
|
For the next page selection, we have to use several loops in order to select a page. For instance: - first find a page on the current level
- then look at the child page level
- then search the parent level
The ordering of the level and the test conditions can change, but the developer needs to go at least thru one complete loop before checking the page list with another condition. So we provide an array of callbacks, and the developer might
add as many of those, each which its own conditions. So - in the c_site_spider CLASS we have the callback array:
c_site_spider= class(c_spider)
m_oa_on_select_url: array of t_po_accept_url;
// -- ...
end; // c_site_spider
|
- the user adds the methods definitions in the tForm CLASS:
TForm1= class(TForm)
// ...
private
procedure select_next_page_child(p_c_url: c_url; var pv_accept: Boolean);
procedure select_next_page_parent_images(p_c_url: c_url; var pv_accept: Boolean);
end; // tForm1
| - with, for instance, the following implementation:
procedure TForm1.select_next_page_child(p_c_url: c_url; var pv_accept: Boolean);
begin
with g_c_spider do
pv_accept:= f_is_child_page(p_c_url) and f_is_html_extension(p_c_url);
end; // select_next_page_child
procedure TForm1.select_next_page_parent_images(p_c_url: c_url;
var pv_accept: Boolean);
begin
with g_c_spider do
pv_accept:= f_is_domain_page(p_c_url) and not f_is_child_page(p_c_url)
and (p_c_url.m_extension= '.png');
end; // select_next_page_parent_images
| - and the callbacks are initialzes with:
procedure TForm1.goClick(Sender: TObject);
begin
// ...
with g_c_spider do
begin
append_selection_procedure(select_next_page_child);
append_selection_procedure(select_next_page_parent_images);
// -- ...
|
Care must be taken to correctly synchronize the filtering and the selection. If the selection is more stringent than the filtering, the download panel and the
"todo pages" list will display pages which will never be downloaded.
3.4 - The delfault strategy The default strategy then implements a "usual" reasonable choice. We hard coded the following choices:
- everything from the current page
- the .HTML from the children
- the images from the parent
This could have been hard coded into the c_site_spider, but since we have a
general call-back system, we simply initialized the call back to this strategy when none was set by the user interface or by the custom call-backs.
3.5 - The main form
The main form is nearly the same as the one used for the downloader. We simply added: - a c_find_memo, which can sort the pages which will not be downloaded. This can be used to perform a first analysis:
- we fist donwload the the main target URL
- the "other pages" displays all anchor tags in this page
- when clicking "sort", we easily see what is in the page itself, the child pages, the other domains etc
- the speed button filter selection, which have been displayed above.
Here is the snapshot of the project (a page about "OO and Architecture-based Testing"): 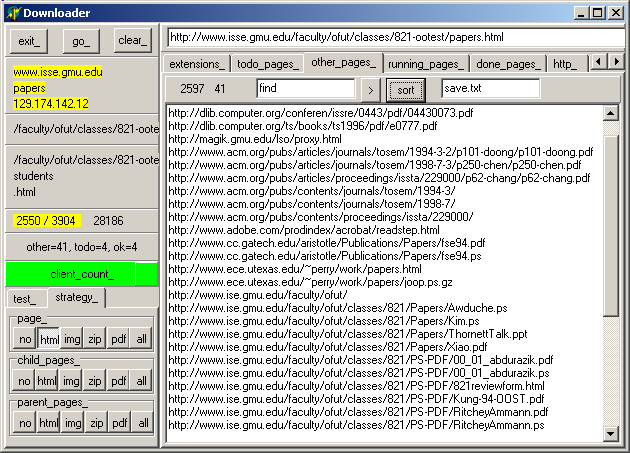
4 - Improvements Among the possible improvements: - start the filtering at the tag-analysis level (not after adding the tags to the file list)
- improve the GUI selection functionality: buiding the usual expression building technique (the kind found in Quick Report, for instance)
- start the download in parallel instead of using a page after page limit
- build a more abstract and generic "spidering API"
5 - Download the Sources Here are the source code files:
Those .ZIP files contain: - the main program (.DPR, .DOF, .RES), the main form (.PAS, .DFM), and any other auxiliary form
- any .TXT for parameters
- all units (.PAS) for units
Those .ZIP
- are self-contained: you will not need any other product (unless expressly mentioned).
- can be used from any folder (the pathes are RELATIVE)
- will not modify your PC in any way beyond the path where you placed the .ZIP
(no registry changes, no path creation etc).
To use the .ZIP: - create or select any folder of your choice
- unzip the downloaded file
- using Delphi, compile and execute
To remove the .ZIP simply delete the folder.
As usual: - please tell us at fcolibri@felix-colibri.com if you found some errors, mistakes, bugs, broken
links or had some problem downloading the file. Resulting corrections will be helpful for other readers
- we welcome any comment, criticism, enhancement, other sources or reference
suggestion. Just send an e-mail to fcolibri@felix-colibri.com.
- or more simply, enter your (anonymous or with your e-mail if you want an
answer) comments below and clic the "send" button
- and if you liked this article, talk about this site to your fellow
developpers, add a link to your links page ou mention our articles in your blog or newsgroup posts when relevant. That's the way we operate: the more traffic and Google references we get, the more articles we will write.
6 - Conclusion We presented in this paper a Web Spider, allowing the disc storage of all the pages of a web site. Filtering and Selection allow to guide the process and avoid overflooding.
7 - The author
Felix John COLIBRI works at the Pascal Institute. Starting with Pascal in 1979, he then became involved with Object Oriented Programming, Delphi, Sql, Tcp/Ip, Html, UML. Currently, he is mainly
active in the area of custom software development (new projects, maintenance, audits, BDE migration, Delphi
Xe_n migrations, refactoring), Delphi Consulting and Delph
training. His web site features tutorials, technical papers about programming with full downloadable source code, and the description and calendar of forthcoming Delphi, FireBird, Tcp/IP, Web Services, OOP / UML, Design Patterns, Unit Testing training sessions.
|