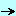|
RSS Reader - Felix John COLIBRI. |
- abstract : Download and View the content of an .RSS feed (the entry point into somebody's blog)
- key words : .RSS - Blog - HTTP Client - HTTP downloader - XML parser - tTreeView
- software used : Windows XP, Delphi 6
- hardware used : Pentium 2.800Mhz, 512 M memory, 140 G hard disc
- scope : Delphi 1 to 2006, Turbo Delphi for Windows, Kylix
- level : Delphi developer
- plan :
1 - Introduction We started our own
Delphi blog a week ago (october 30th 2006). To write our blog, we had to learn about the structure, formats and rules about blogging. The best way to learn this new business was to look at other people's blogs. We already knew
that blogging was associated with "RSS" but did not grasp the concept. So we looked at a couple of web tutorials, and then at the .RSS specification. The result of the whole effort was an .RSS analyzer, which quickly was put in bed
with an .HTTP downloader, and we present here the complete project. Before we start: - this is not a full blown "blog reader". We only display the raw content of the .RSS file
- this is not a "blog aggregator": we do not manage the downloaded items, and do not save them by topic, date etc.
- for our daily blog reading, we look at the excellent Delphi
Feeds site which presents in real time the new blog items from a selected 50 Delphi blog sites
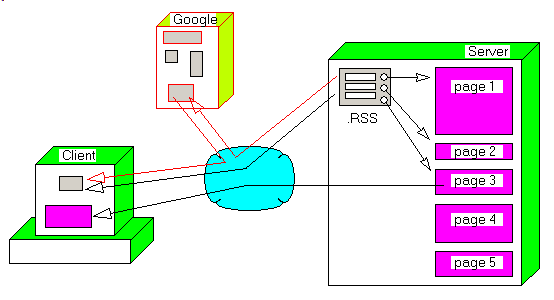
2 - Basic blog architecture 2.1 - quick history
A blog is a collection of .HTML files downloadable from the Web. An Internet diary. Here is a graphical representation of the blog architecture:
2.2 - The .RSS specification This .RSS structure was quickly considered inadequate, and many new versions of the same thing were proposed.
You will easily find lots of pages on the Web telling you the complete story. We will stick to the 2.0 version, which seems to be the most popular. The specification can be found at the RSS Advisory
Board site. However this is a narrative document, not a compiler-like specification.
To explain the structure of an .RSS file, the easiest way is to display a short example.
- on our site, http://www.felix-colibri.com, we have (among all other) 3 pages:
- a simple .RSS file for those three items would be:
<?xml version="1.0" encoding="ISO-8859-1"?>
<rss version="2.0">
<channel>
<title>Felix Colibri's Delphi Blog</title>
<link>http://www.felix-colibri.com/</link>
<description>Delphi source code, training, development, consulting</description>
<item>
<title>Turbo Delphi Interbase tutorial</title>
<link>http://www.felix-colibri.com/blog/turbo_delphi_interbase_tutorial_.html</link>
<description>develop database applications with Turbo Delphi and Interbase. Complete ADO Net architecture, and full projects to create the database, the Tables, fill the rows, display and update the values with DataGrids. Uses the BDP</description>
</item>
<item>
<title>Delphi 2006 for .NET training classes</title>
<link>http://www.felix-colibri.com/blog/delphi_2006_for_net_course_.html</link>
<description>dedicated to Windows Forms and Web Form classes (not Win32 nor VCL.NET), with special emphasis on ADO.NET database management, and the development of ASP.NET applications</description>
</item>
<item>
<title>Abstract Factory and Bridge Design Patterns</title>
<link>http://www.felix-colibri.com/blog/factory_and_bridge_patterns_.html</link>
<description>Delphi version of the Abstract Factory and Bridge patterns, as used in our Lexi Document Editor. Presentation of the patterns, with UML diagrams and full downloadable source code.</description>
</item>
</channel>
</rss>
|
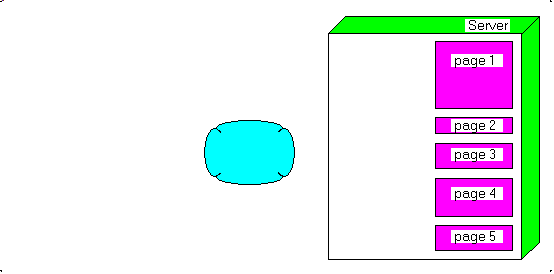
It is easy to see that the .RSS is a simple .XML file, with 2 kind of elements - a single element with the blog site attributes (site URL, title, copyright etc)
- for each blog page, an individual element with the page attributes (page URL, title, description, publication date)
Our presentation is not complete: .RSS files have many more attributes, like
publication date, copyright, language and so on. You might have a look at the full blown RSS specification for more details. But most of the .RSS that we analyzed respected the following BNF-like grammar:
rss_file= xml_version rss .
rss= RSS channel E_RSS .
channel= CHANNEL header { item } E_CHANNEL .
title= TITLE 'title' E_TITLE .
link= LINK 'link' E_LINK .
descritpion= DESCRIPTION 'description' E_DESCRIPTION .
header= title link descripion .
item= title link description .
|
Naturally, we can throw in all kind of optional attributes, like publication date, copyright etc. Here is the structure which WE use for our own .RSS:
rss_file= xml_version rss .
rss= RSS channel E_RSS .
channel= CHANNEL header { item } E_CHANNEL .
title= TITLE 'title' E_TITLE .
link= LINK 'link' E_LINK .
descritpion= DESCRIPTION 'description' E_DESCRIPTION .
category= CATEGORY 'category' E_CATEGORY .
pubdate= PUBDATE 'publication date' E_PUBDATE.
header= title link descripion language copyright category doc pubdate .
language= LANGUAGE 'language' E_LANGUAGE .
copyright= COPYRIGHT 'copyright' E_COPYRIGHT .
doc= DOC 'doc' E_DOC .
item= title link description category pubdate guid .
guid= GUID 'guid' GUID .
|
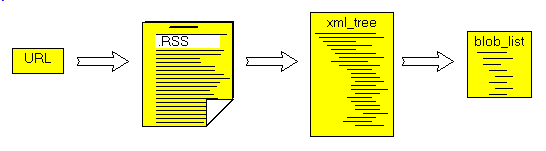
So, to analyze the blog - we used our .XML parser to extract the .XML elements and build an .XML tree
- we followed the grammar to get the .RSS information in a more efficent structure
- this structure was then used
- to display the relevant parts of the .RSS
- to build a tTreeView allowing to examine each part of the .RSS file individually
Let's present the Delphi project
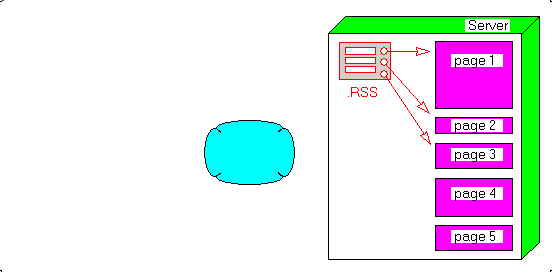
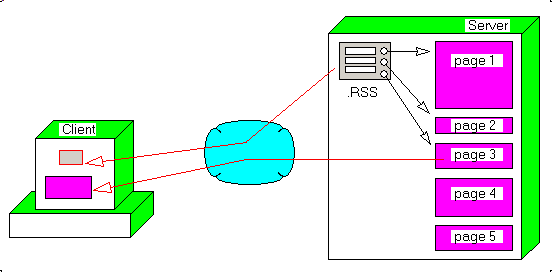
3 - The Delphi .RSS reader 3.1 - The CLASS architecture We will use - an HTTP reader to download the individual .RSS file from the URL
- an .XML parser CLASS which produces an .XML Tree
- an RSS parser which extracts a blog information structure from the .XML Tree
Graphically, we have:
3.2 - The HTTP downloader We start with a list of .RSS URLS. The .RSS file is located on the same server as the blog pages, and the pages presented by any web browser (Internet Explorer, for instance) contain a link
to this file, often a CGI button with an icon looking like any of those: By retrieving the ULR associated with the button, you can collect the .RSS URL. Here are a couple of .RSS URLS:
http://blogs.teamb.com/craigstuntz/Rss.aspx
http://feeds.feedburner.com/gurock.xml
http://blogs.borland.com/davidi/Rss.aspx
http://www.felix-colibri.com/feed.rss | By clicking on the button, you can download the .RSS file. But this file will be static (you will only get the .RSS you downloaded at this moment). A couple
of days later, the content of the .RSS will have changed, to reflect any new blog page. So it seems appropriate to download the .RSS by using the URL, rather than donwloading manually the .RSS file each time we want to know what's new.
HTTP seems also a good choice, since this is the preferred way to handle web pages. We already presented many ways to retrieve .HTML content using .HTTP clients, mainly using WinSocket encapsulations. In this case, we will use a
tClientSocket which is one level above the WinSocket. The detail of the use of this component for .HTML download has been presented elsewhere (google for +colibri+http+client, for instance).
We simply wrapped the tClientSocket in a thin CLASS which contains a c_byte_buffer to receive the content of the .HTTP request. The definition of this CLASS is:
c_http_client= class; // Forward
t_po_received_event= Procedure(p_c_http_client: c_http_client) of Object;
c_http_client= class(c_basic_object)
m_c_client_socket: tClientSocket;
m_c_url: c_url;
m_c_reception_buffer: c_byte_buffer;
m_total_received_bytes: Integer;
m_on_received_event: t_po_received_event;
Constructor create_http_client(p_name: String);
procedure handle_socket_error(p_c_client_socket: tObject;
p_c_winsocket: TCustomWinSocket;
p_error_event: TErrorEvent; var pv_error_code: Integer);
procedure handle_after_connection(p_c_client_socket: tObject;
p_c_winsocket: TCustomWinSocket);
procedure handle_write(p_c_client_socket: tObject;
p_c_winsocket: TCustomWinSocket);
procedure handle_read(p_c_client_socket: tObject;
p_c_winsocket: TCustomWinSocket);
procedure disconnect;
procedure handle_after_disconnection(p_c_client_socket: tObject;
p_c_winsocket: TCustomWinSocket);
procedure connect;
procedure download_page(p_url: String;
p_po_received_event: t_po_received_event);
Destructor Destroy; Override;
end; // c_http_client
| The user of this CLASS will
- call download_page to start the download
- initialize the m_on_received_event to be notified about the end of the reception
3.3 - The .XML Scanner and .XML Parser
Once the page is downloaded, we will extract the .XML content using an .XML scanner and a generic .XML parser. The result of the parsing will be a general c_xml_tree structure, with contains all the information of the original .RSS
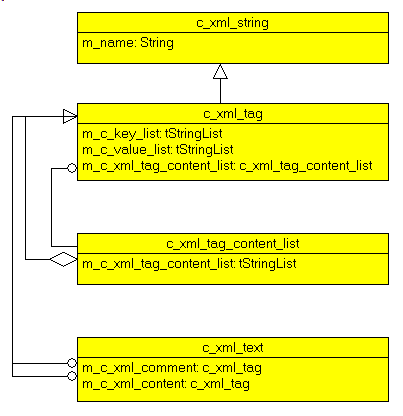
file, bug in a tree structure instead of a text buffer. The .XML structure is organized as follows
The c_xml_tag contains a list of sub tabs and text (c_xml_tag_content_list), and this structure is itself made of c_strings or c_tags. The UML CLASS diagram of this structure is:
3.4 - The Blog List The .RSS file basically contains - the header
- a list of items
So basically it is a list of items, and the traditional tStringList
encapsulation can be used:
3.5 - The Blog Reader The main CLASS then uses all the previous pieces to download the .RSS file,
pass it into a c_xml_text, and transform the tree into a c_blog_item_list:
c_blog_reader= class; // forward
t_po_blog_reader_event= Procedure(p_c_blog_reader: c_blog_reader) of Object;
c_blog_reader= class(c_basic_object)
m_rss_path, m_rss_file_name: String;
m_rss_url: String;
// -- the content of the .RSS
m_c_rss_content: tStringList;
m_c_http_client: c_http_client;
m_on_downloaded_rss: t_po_blog_reader_event;
// -- the result of the .XML parser
m_c_xml_text: c_xml_text;
// -- the .XML tree in a more palatable (blog) presentation
m_c_blog_item_list: c_blog_item_list;
// -- stats
m_rss_size: Integer;
Constructor create_blog_reader(p_name: String);
function f_rss_url_to_file_name(p_rss_url: String): String;
procedure download_rss(p_rss_url: String;
p_on_downloaded_rss: t_po_blog_reader_event);
procedure handle_received_rss_feed(p_c_http_client: c_http_client);
procedure load_rss_file(p_rss_path, p_rss_file_name: String);
procedure analyze_rss;
procedure _build_blog_item_list;
Destructor Destroy; Override;
end; // c_blog_reader
|
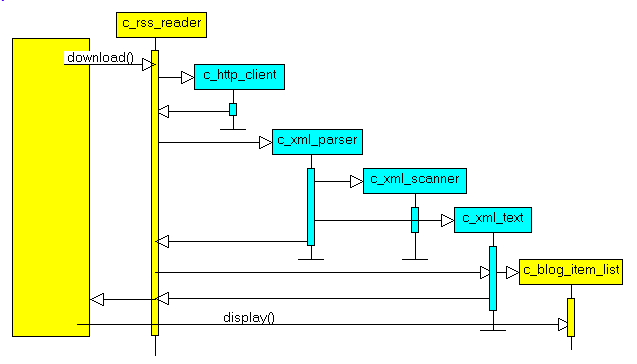
3.6 - The behaviour of the Classes The following UML sequence diagram shows the scenario of an .RSS download and display (in blue the transient CLASSes):
3.7 - The main Form
Here is an example of usage: - we store on disk a list of interesting .RSS urls
- this list can be found using e tDirectoryListbox / tFileListbox combination. The selected list is displayed in a tListBox
- clicking on a tListBox item will start the download. The resulting file will be saved (for any later analysis, if required)
- the same file can be handed over to the .XML scanner / parser top produce an
.XML tree. And this tree will be transformed into a c_blog_item_list
- the c_blog_item_list is displayed in a tTreeView, where clicking on a tTreeNode will display the blog item (URL, description, for instance)
3.8 - Mini Manual To use the program  | store the URLS of .RSS files which are of interest to you on disk
| |
| compile and execute the project
| | |
in the "dir" tab of the left tNoteBook, select this file: 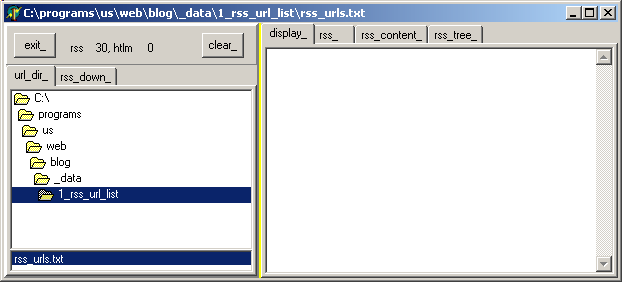 |  |
the tListBox in the "rss_donwload_" tab will display the list of URLS: 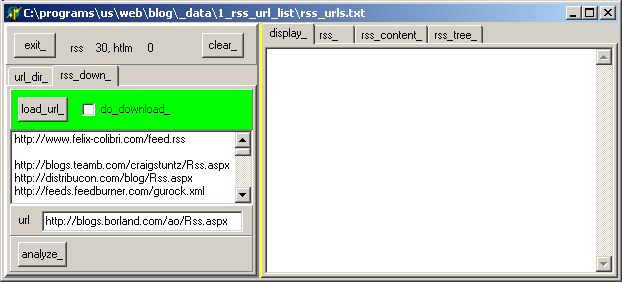 | | |
select one of the URLs. In our case "Craig Stuntz" | | | after (some) seconds, the file is downloaded, and can be viewed in the
"rss_" tab of the right tNoteBook | | | to build the blog item list, and fill the tTreeView, click "analyze" | |
| the tTreeView is filled 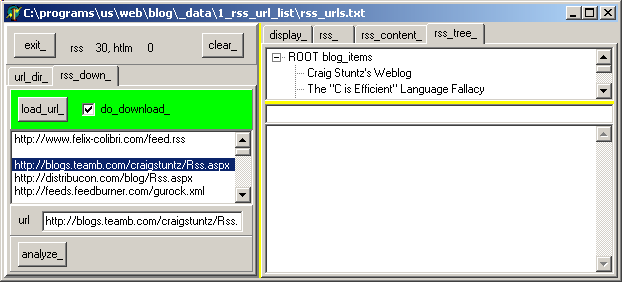 | |
| clic on any tTreeNode to display its content. In our case, "the 'C is efficient' language fallacy". Of course. And I could easily add C++, Java
and C# to the list, but that's another story. | | | the URL of the item and the description are displayed:
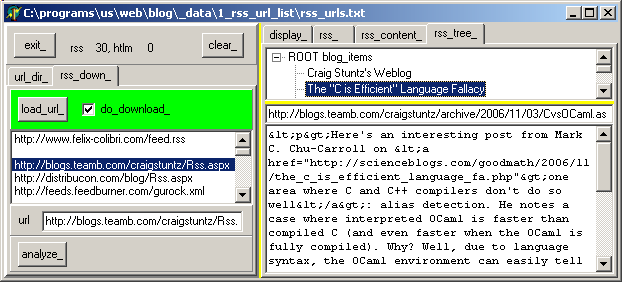
|
4 - Comments and Improvements 4.1 - The components
This projects was built in a couple of days, and much can be improved. Mainly by using other components - to download an .HTTP page, we could use any of the shrink wrapped .HTTP components (Indy, ICS, even NetManage)
- the parsing of the .XML could also be performed using the different SAX or DOM engines. In addition, having installed Turbo Delphi, we already have installed, by necessity, the Microsoft .XML machinery. And since Delphi 6,
we have an tXMLDocument, provided specially for .XML handling
- I am not convinced that our .XML representation is the best, but it was created to to handle XML EDI applications for one of our customer project,
which were specified using nested .XSD files, and this structure prooved adequate in this circumstance. So ...
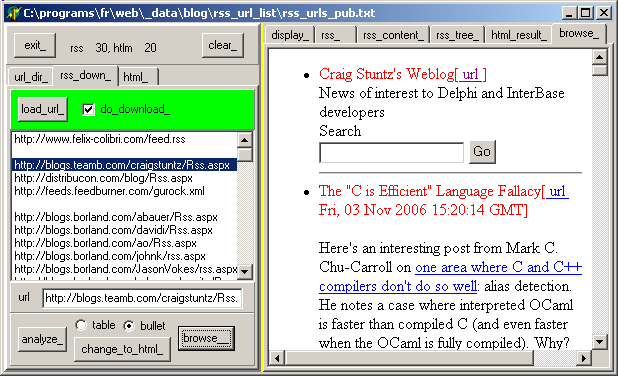
4.2 - What's next ? Looking at the last snapshot, you may think that the content is not very
readable. The reason is that the description has been HTML-encoded. For instance "<" is displayed as "@gt;". The second is that if the feed description contains any .HTML link, we cannot
click them. To do so requires some .HTML rendering with HREF-links clicking functionality. This will be presented in a future paper, but, to wet your appetite, here is the result, on the same blog:
 If some of you are in a real hurry to put your hand on this, just send me an
e-mail at fcolibri@felix-colibri.com, and I will see what I can do for you ...
5 - Download the Sources Here are the source code files:
- rss_reader.zip: the full .RSS downloader / analyzer project, including the c_http_client, the .XML scanner and .XML parser, and the filling of the tTreeview (79 K)
We did not include the .HTML renderer (coming soon). We also included a small .RSS url list, as well as a sample .RSS file, to allow analysis, just in case
The .ZIP file(s) contain:
- the main program (.DPR, .DOF, .RES), the main form (.PAS, .DFM), and any other auxiliary form
- any .TXT for parameters, samples, test data
- all units (.PAS) for units
Those .ZIP
- are self-contained: you will not need any other product (unless expressly mentioned).
- for Delphi 6 projects, can be used from any folder (the pathes are RELATIVE)
- will not modify your PC in any way beyond the path where you placed the .ZIP (no registry changes, no path creation etc).
To use the .ZIP: - create or select any folder of your choice
- unzip the downloaded file
- using Delphi, compile and execute
To remove the .ZIP simply delete the folder. The Pascal code uses the Alsacian notation, which prefixes identifier by
program area: K_onstant, T_ype, G_lobal, L_ocal, P_arametre, F_unction, C_lasse etc. This notation is presented in the Alsacian Notation paper.
As usual:
- please tell us at fcolibri@felix-colibri.com if you found some errors, mistakes, bugs, broken links or had some problem downloading the file. Resulting corrections will
be helpful for other readers
- we welcome any comment, criticism, enhancement, other sources or reference suggestion. Just send an e-mail to fcolibri@felix-colibri.com.
- or more simply, enter your (anonymous or with your e-mail if you want an answer) comments below and clic the "send" button
- and if you liked this article, talk about this site to your fellow developpers, add a link to your links page ou mention our articles in your blog or newsgroup posts when relevant. That's the way we operate:
the more traffic and Google references we get, the more articles we will write.
6 - References A couple of useful links: - DelphiFeeds The excellent
Delphi Feeds site, which scans every hour a list of about 50 Delphi blogs, and presents the daily news. I contacted them as soon as I had my blogs established. Dennis Gurock contacted me on this very
saturday afternoon to tell me that my .RSS had some problem (I had uploaded the .RSS but forgotten to upload the pages !), and acknowledged the success of the correction. Thats efficiency
- "The BDN Guide to RSS or "A simple introduction to using the BDN RSS feeds and writing applications which produce or consume RSS." - by Craig Stuntz
Why did I choose Craig's blog as an example ? There are a couple of reasons: - when I was preparing our Borcon presentation about the Interbase Engine conceptual structure, I spent a lot of time on the Web looking for
additional information. Craig's site was one of the best Interbase + Delphi site I could find. However some pages could not be presented correctly, and I believe now that it was because I was looking at the RSS and not at the .HTML page !
- second, he was one of the first to jump into the Delphi Blog bandwagon. He even published the above mentioned paper, telling where a Delphi blogger could find some help. And his paper mentions two Delphi for .Net
tools which are source code (see below)
- finally, having decided to use his blog as an example, I found that his last blog entry was about the "C fallacy". Nothing new since 1979. The
blog entry must be about some compiler technique, but debunking the C (and similar) myth is always good news. "Make it simple, but no more" was Niklaus WIRTH's motto (from an Einstein quote). I fully adhere to this,
as many of WIRTH's hundreds of "virtual children". I will blog about this some day. And it will have nothing to do with Pascal vs C bigottery, but about dollars. That's a language most developers (and even product managers) understand.
- ASP.Net Blog Engine by John Moshakis: a Delphi ASP.Net blog engine using Cassini
- Delphi for .NET RSS
aggregator by Chris Dickerson. Another Delphi .Net aggregator. Only downloadable by Delphi registered members
- SimpleRSS by
Robert MacLean. A delphi component that allows you to work with feeds (Atom, RSS, RDF, iTunes) directly (importing and exporting feeds) from Delphi, and Kylix. We quickly looked at it, and its the most complete Delphi .RSS
component we found. For instance, four our blog we hard coded the language to "us-en", but this component has constants for all the languages in the official specification. This component's new version can also be found using Google: +"BlueHippo"
- the RSS Specification can be found at RssBoard.Org
7 - The author
Felix John COLIBRI works at the Pascal Institute. Starting with Pascal in 1979, he then became involved with Object Oriented Programming, Delphi, Sql, Tcp/Ip, Html, UML. Currently, he is mainly
active in the area of custom software development (new projects, maintenance, audits, BDE migration, Delphi
Xe_n migrations, refactoring), Delphi Consulting and Delph
training. His web site features tutorials, technical papers about programming with full downloadable source code, and the description and calendar of forthcoming Delphi, FireBird, Tcp/IP, Web Services, OOP / UML, Design Patterns, Unit Testing training sessions.
|