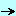|
DFM Parser - Felix John COLIBRI. |
- abstract : This project parses the content of a .DFM text and builds an in-memory tree of its content
- key words : .DFM, parser, BNF, EBNF, IEBNF, scanner
- software used : Windows XP, Delphi 6
- hardware used : Pentium 1.400Mhz, 256 M memory, 140 G hard disc
- scope : Delphi 1 to 2005 for Windows, Kylix
- level : Delphi developer
- plan :
1 - Introduction
When we download open source Delphi projects, it sometimes happens that all the components are not included with the project. Therefore we have created a utility which reconstitutes the components, simply analyzing the client code.
This utility examines the .Dfm and the .Pas, finding all the Class fields and methods to rebuild a "shadow" component which then can be included in the project. The first step of this utility is to analyze the .Dfm. The analysis is
performed by parsing the .Dfm and storing the content in a tree-like structure. The parser and the structure are presented in this paper.
2 - The Delphi Dfm Parser
2.1 - Binary and Textual .DFM Our parser only analyses textual .Dfm files. If the .Dfm you wish to analyze is in binary format, we use CONVERT.EXE which is a binary to text conversion
utility located in the BIN folder of Delphi (since Delphi 1). In fact we use a utility which converts all the binary .Dfms in a path to their textual form. This is simple to do and will not be shown here.
2.2 - The Structure of a .DFM A .Dfm is organized in a hierarchical way, showing each component placed on the tForm and the properties whose values are not the default values initialized by the CONSTRUCTOR.
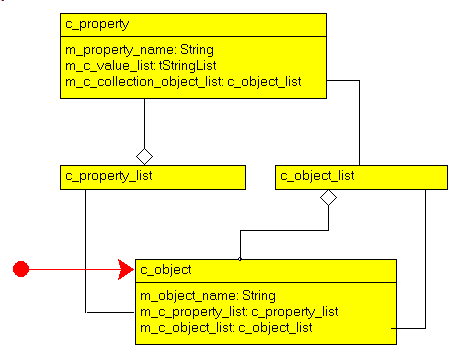
Here is a simple Delphi Form: 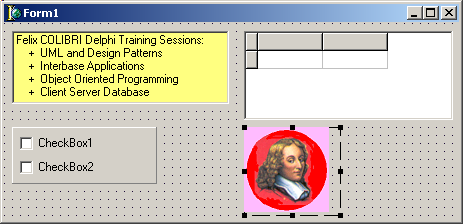 If we select "View as Text" in the contextual menu of the Form Designer, we see the following .Dfm content:
object Form1: TForm1
Left = 192
Top = 107
Width = 463
Height = 224
Cursor = crHourGlass
Caption = 'Form1'
Color = clBtnFace
Font.Charset = DEFAULT_CHARSET
Font.Color = clWindowText
Font.Height = -11
Font.Name = 'MS Sans Serif'
Font.Style = []
OldCreateOrder = False
PixelsPerInch = 96
TextHeight = 13
object ListBox1: TListBox
Left = 8
Top = 8
Width = 217
Height = 73
Color = 8454143
ItemHeight = 13
Items.Strings = (
'Felix COLIBRI Delphi Training Sessions:'
' + UML and Design Patterns'
' + Interbase Applications'
' + Object Oriented Programming'
' + Client Server Database')
TabOrder = 1
end
object DBGrid1: TDBGrid
Left = 240
Top = 8
Width = 209
Height = 89
Options = [dgTitles, dgIndicator, dgColumnResize, dgColLines, dgRowLines, dgTabs, dgRowSelect, dgConfirmDelete, dgCancelOnExit]
TabOrder = 0
TitleFont.Charset = DEFAULT_CHARSET
TitleFont.Color = clWindowText
TitleFont.Height = -11
TitleFont.Name = 'MS Sans Serif'
TitleFont.Style = []
Columns = <
item
Expanded = False
Visible = True
end
item
Expanded = False
Visible = True
end>
end
object Panel1: TPanel
Left = 8
Top = 104
Width = 145
Height = 57
TabOrder = 2
object CheckBox1: TCheckBox
Left = 8
Top = 8
Width = 97
Height = 17
Caption = 'CheckBox1'
TabOrder = 0
end
object CheckBox2: TCheckBox
Left = 8
Top = 32
Width = 97
Height = 17
Caption = 'CheckBox2'
TabOrder = 1
end
end
object Image1: TImage
Left = 240
Top = 104
Width = 97
Height = 89
Picture.Data = {
07544269746D617036550000424D365500000000000036000000280000005500
000055000000010018000000000000550000C40E0000C40E0000000000000000
// -- removed
FFBBFFFFBBFFFFBBFFFFBBFFFFBBFFFFBBFFFFBBFFFFBBFFFFBBFFFFBBFFFFBB
FF16}
end
end
|
The coding conventions of the .Dfm file are as follows: - for simple types (Integer, Boolean, String, ), the value is simply saved after "="
object Form1: TForm1
Left = 192
Cursor = crHourGlass
Caption = 'Form1'
Color = clBtnFace
OldCreateOrder = False
...
end | - for sets, the values are stored between "[" and "]"
object DBGrid1: TDBGrid
...
Options = [dgTitles, dgIndicator, dgColumnResize, dgColLines,
dgRowLines, dgTabs, dgRowSelect, dgConfirmDelete, dgCancelOnExit]
...
TitleFont.Style = []
...
end
| - for tStrings and tList, the values are between "(" and ")":
object ListBox1: TListBox
...
Items.Strings = (
'Felix COLIBRI Delphi Training Sessions:'
' + UML and Design Patterns'
' + Interbase Applications'
' + Object Oriented Programming'
' + Client Server Database')
...
end
| - for binary values (bitmaps for glyphs etc), the hexadecimal content is saved between "{" and "}"
object Image1: TImage
...
Picture.Data = {
07544269746D617036550000424D365500000000000036000000280000005500
000055000000010018000000000000550000C40E0000C40E0000000000000000
...
FF16}
...
end |
- for collections, the delimiters are "<" and ">", with each item in between. And for each item, between the item name and "end", we have the property name and value
object DBGrid1: TDBGrid
...
Columns = <
item
Expanded = False
Visible = True
end
item
Expanded = False
Visible = True
end>
...
end
| - for sub properties (like Font), the property name is composed with the
property name and the sub-property name:
object Form1: TForm1
...
Font.Charset = DEFAULT_CHARSET
Font.Color = clWindowText
Font.Height = -11
Font.Name = 'MS Sans Serif'
Font.Style = []
...
end |
- components dropped on a container are nested within the container definition:
object Form1: TForm1
...
object Panel1: TPanel
...
object CheckBox1: TCheckBox
Left = 8
...
end
end
...
end |
We did not find other cases, but did not check the Delphi Sources, which would determine all the possibilities.
2.3 - .Dfm Grammar
In order to parse the .Dfm content, we first started to build a grammar. We are using recursive descent parsing since 1980, as explained by Niklaus WIRTH, and have automated the parsing process, like so many other programmers have done
(Yacc: Yet Another Compiler's Compiler). Let us present a simple example here. A simple arithmetic expression like:
value:= amount * ( 1+ rate / 100.0 ); | can be analyzed by the following grammar:
assignment= NAME ':=' expression ';' .
expression= [ '+' | '-' ] term { ( '+' | '-' ) term } .
term= factor { ( '*' | '/' ) factor } .
factor= NUMBER | NAME | '(' expression ')' .
| This grammar is recursive, since expression calls term, which calls factor, which calls expression. However the "entry point" is always expression, and
never "factor". Therefore, a possible Pascal structure for a parser could be:
PROCEDURE parse_assignment;
PROCEDURE parse_expression;
PROCEDURE parse_term;
PROCEDURE parse_factor;
BEGIN
CASE f_symbol_type OF
e_string_litteral_symbol : read_symbol;
e_integer_litteral_symbol:
read_symbol;
e_IDENTIFIER_symbol :
read_symbol;
e_opening_parenthesis_symbol :
BEGIN
read_symbol;
parse_expression;
check(e_closing_parenthesis_symbol);
read_symbol;
END; // n
ELSE display_error('NUMBER, NAME, (');
END; // case
END; // parse_factor
BEGIN // parse_term
parse_factor;
WHILE f_symbol_type IN [e_times_symbol, e_divide_symbol] DO
BEGIN
IF f_symbol_type IN [e_times_symbol, e_divide_symbol]
THEN read_symbol
ELSE display_error('*, /');
parse_factor;
END; // WHILE
END; // parse_term
BEGIN // parse_expression
parse_term;
WHILE f_symbol_type IN [e_plus_symbol, e_minus_symbol] DO
BEGIN
IF f_symbol_type IN [e_plus_symbol, e_minus_symbol]
THEN read_symbol
ELSE display_error('+, -');
parse_term;
END; // WHILE
END; // parse_expression
BEGIN // parse_assignment
// -- skip the lhs
read_symbol;
check(e_assign_symbol);
// -- skip ":="
read_symbol;
parse_expression;
check(e_semi_colon_symbol);
read_symbol;
END; // parse_assignment
| Notice that the parse_factor procedure is nested in the parse_term procedure,
which is nested in the parse_expression procedure, which is nested in the parse_assignment procedure.
Therefore we are using the Indented Extended Backus Naur Formalism to
specify a grammar. In our case, the grammar would be:
assignment= NAME ':=' expression ';' .
expression= [ '+' | '-' ] term { ( '+' | '-' ) term } .
term= factor { ( '*' | '/' ) factor } .
factor= NUMBER | NAME | '(' expression ')' .
| The indentation has the same benefit as indentation in a programming language, or the chapter in a book: it helps structure the program, the book, or the
specification in our case. In addition we use a "folding editor" when we build the grammar (the same technique that Delphi added to Delphi 2005 editor: we can edit "by level").
I am fully aware that this nesting is not politically correct. In our days of object programming, we are supposed to put all the procedures in the CLASS, and this will yield smaller procedures, and also give other a chance to reuse
these procedures. The data is transfered from call to call either thru parameters, or by using CLASS "mailbox" attributes: the caller saves the values there, and the callee grabs them from the attributes. So finding today
nesting beyond level 1 is quite rare. Wirth went down to the level 8 in the P4 compiler, and if it was good enough for Wirth, is certainly is good enough for me. Therefore I am not afraid to nest whenever I can. And if you have deep
recursive programs, you will get used to nest local data and combine value or variable parameters to avoid the declarations of over-parametrized procedures only called from one place, and of those mailbox attributes. In fact, locality
is the name of the game: if you understand local variables, then you should understand the benefit of nesting procedures. For our little expression grammar, or even for the .Dfm grammar below, it does not make any difference
whether you nest or not. But when the grammar increases in size (Pure Pascal: 100 lines, Delphi: 300, Sql: 500 for Interbase, beyond 3.000 for Sql 92) then structuring becomes important.
We are using this IEBNF since a long time. And we have grammars for nearly everything: for Delphi, for C, Java, C++, for HTML, Oberon, Sql, Interbase eSql, Pdf, Zip etc. Just give us a name and we have a grammar for it. Some of
my friends call me a grammar junkie. Whenever I have to spelunk into some kind of structured information, I build the grammar first, launch the parser generator and start programming from there.
In the case of the .Dfm grammar, the structure is the following:
dfm= object .
object= OBJECT NAME ':' TYPE_NAME
property { property } { object } END .
property= NAME [ '.' NAME ] '=' value .
value= INTEGER | DOUBLE | TRUE | FALSE | STRING
| NAME [ '.' NAME ]
| '[' [ value { ',' value } ] ']'
| '(' value { [ '+' ] value } ')'
| '{' value { value } '}'
| '<' collection_item { collection_item } '>' .
collection_item= NAME property { property } END .
|
2.4 - The Scanner The scanner is quite easy to write. The definition is the following:
t_dfm_symbol_type= (e_unknown_symbol,
e_integer_symbol, e_double_symbol, e_string_litteral_symbol,
e_colon_symbol, e_equal_symbol, e_point_symbol,
e_comma_symbol, e_plus_symbol,
e_opening_parenthesis_symbol, e_closing_parenthesis_symbol,
e_opening_bracket_symbol, e_closing_bracket_symbol,
e_opening_brace_symbol, e_closing_brace_symbol,
e_lower_symbol, e_greater_symbol,
e_identifier_symbol,
e_object_symbol, e_end_symbol,
e_TRUE_symbol, e_FALSE_symbol,
e_end_of_parse_symbol,
);
c_dfm_scanner= class(c_text_file)
m_dfm_symbol_type: t_dfm_symbol_type;
m_blank_string, m_symbol_string: String;
// -- accept as number values starting with A..Z
m_in_brace: Boolean;
constructor create_dfm_scanner(p_name, p_file_name: String);
function f_initialized: Boolean;
function f_read_symbol: Boolean;
destructor Destroy; Override;
end; // c_dfm_scanner
|
The main routine which isolates one symbol is (not all methods shown):
function c_dfm_scanner.f_read_symbol: Boolean;
procedure get_identifier;
var l_start: Integer;
begin
m_dfm_symbol_type:= e_identifier_symbol;
l_start:= m_buffer_index;
while (m_buffer_index< m_buffer_size) and (m_pt_buffer[m_buffer_index] in k_identifier) do
inc(m_buffer_index);
m_symbol_string:= f_extract_string_start_end(l_start, m_buffer_index- 1);
if m_symbol_string= 'object'
then m_dfm_symbol_type:= e_object_symbol else
if m_symbol_string= 'end'
then m_dfm_symbol_type:= e_end_symbol else
if LowerCase(m_symbol_string)= 'true'
then m_dfm_symbol_type:= e_true_symbol else
if LowerCase(m_symbol_string)= 'false'
then m_dfm_symbol_type:= e_false_symbol else
end; // get_identifier
// -- ... the other extraction procedure here
begin // f_read_symbol
m_symbol_string:= '';
m_dfm_symbol_type:= e_unknown_symbol;
if f_end_of_text
then begin
Result:= False;
m_dfm_symbol_type:= e_end_of_parse_symbol;
end
else begin
get_blanks;
if m_buffer_index< m_buffer_size
then begin
case m_pt_buffer[m_buffer_index] of
'a'..'z', 'A'..'Z' :
if m_in_brace and (m_pt_buffer[m_buffer_index] in k_hex_digits)
then get_number
else get_identifier;
'-', '0'..'9' : get_number;
':' : get_one_operator(e_colon_symbol);
'.' : get_one_operator(e_point_symbol);
'=' : get_one_operator(e_equal_symbol);
',' : get_one_operator(e_comma_symbol);
'+' : get_one_operator(e_plus_symbol);
'''': get_string_litteral;
'(' : get_one_operator(e_opening_parenthesis_symbol);
')' : get_one_operator(e_closing_parenthesis_symbol);
'[' : get_one_operator(e_opening_bracket_symbol);
']' : get_one_operator(e_closing_bracket_symbol);
'{' : begin
m_in_brace:= True;
get_one_operator(e_opening_brace_symbol);
end;
'}' : begin
get_one_operator(e_closing_brace_symbol);
m_in_brace:= False;
end;
'<' : get_one_operator(e_lower_symbol);
'>' : get_one_operator(e_greater_symbol);
else
display_bug_stop('unknown_char_in_dfm '+ m_pt_buffer[m_buffer_index]
+ '< '+ IntToStr(Ord(m_pt_buffer[m_buffer_index])));
end; // case
end
else m_dfm_symbol_type:= e_end_of_parse_symbol;
Result:= True;
end; // not eof
end; // f_read_symbol
|
2.5 - The Parser
The parser is derived from our Grammar. It simply checks that the .Dfm selected corresponds to our grammar or not:
PROCEDURE pure_parse_dfm;
PROCEDURE parse_object;
PROCEDURE parse_property;
PROCEDURE parse_value;
PROCEDURE parse_collection_item;
BEGIN
check(e_IDENTIFIER_symbol);
read_symbol;
parse_property;
WHILE f_symbol_type= e_IDENTIFIER_symbol DO
parse_property;
check(e_END_symbol);
read_symbol;
END; // parse_collection_item
BEGIN // parse_value
CASE f_symbol_type OF
e_INTEGER_symbol :
read_symbol;
e_DOUBLE_symbol :
read_symbol;
e_TRUE_symbol :
read_symbol;
e_FALSE_symbol :
read_symbol;
e_STRING_LITTERAL_symbol :
read_symbol;
e_IDENTIFIER_symbol :
BEGIN
read_symbol;
IF f_symbol_type= e_point_symbol
THEN BEGIN
read_symbol;
check(e_IDENTIFIER_symbol);
read_symbol;
END; // IF [
END; // n
e_opening_bracket_symbol :
BEGIN
read_symbol;
IF f_symbol_type IN [e_INTEGER_symbol, e_DOUBLE_symbol,
e_TRUE_symbol, e_FALSE_symbol, e_STRING_LITTERAL_symbol,
e_IDENTIFIER_symbol, e_opening_bracket_symbol,
e_opening_parenthesis_symbol, e_opening_brace_symbol, e_lower_symbol]
THEN BEGIN
parse_value;
WHILE f_symbol_type= e_comma_symbol DO
BEGIN
read_symbol;
parse_value;
END; // WHILE {
END; // IF [
check(e_closing_bracket_symbol);
read_symbol;
END; // n
e_opening_parenthesis_symbol :
BEGIN
read_symbol;
parse_value;
WHILE f_symbol_type IN [e_plus_symbol,
e_INTEGER_symbol, e_DOUBLE_symbol, e_TRUE_symbol, e_FALSE_symbol,
e_STRING_litteral_symbol, e_identifier_symbol, e_opening_bracket_symbol,
e_opening_parenthesis_symbol, e_opening_brace_symbol] DO
BEGIN
if f_symbol_type= e_plus_symbol
then read_symbol;
parse_value;
END; // WHILE {
check(e_closing_parenthesis_symbol);
read_symbol;
END; // n
e_opening_brace_symbol :
BEGIN
read_symbol;
parse_value;
WHILE f_symbol_type IN [e_INTEGER_symbol, e_DOUBLE_symbol,
e_TRUE_symbol, e_FALSE_symbol, e_STRING_LITTERAL_symbol,
e_IDENTIFIER_symbol, e_opening_bracket_symbol,
e_opening_parenthesis_symbol, e_opening_brace_symbol, e_lower_symbol] DO
parse_value;
check(e_closing_brace_symbol);
read_symbol;
END; // n
e_lower_symbol :
BEGIN
read_symbol;
parse_collection_item;
WHILE f_symbol_type= e_IDENTIFIER_symbol DO
parse_collection_item;
check(e_greater_symbol);
read_symbol;
END; // n
ELSE display_error('INTEGER, DOUBLE, TRUE, FALSE, STRING, NAME, [, (, {, <');
END; // case
END; // parse_value
BEGIN // parse_property
parse_object;
check(e_END_symbol);
read_symbol;
END; // parse_object
BEGIN // pure_parse_dfm
parse_object;
END; // |
Knowing that the IDE has build a correct .Dfm is quite an achievement. So the real part starts now: we have to add to the parsing routines the code that performs some useful task.
We can either embed in the parser the code which will work on the .Dfm, or build intermediate structures, which will in turn be used to operate on the .Dfm. We chose the second solution, and will present now the structure that we will build.
Also note that this is quite similar to the handling of .XML files: parsing is trivial, but the difficult part is building the layers that will manipulate the file, either as call backs, or as a tree structure.
The Data Structure
The .Dfm grammar (and the samples) show that the .Dfm is composed of - an object node
- the object contains
- a list of properties
- a list of sub objects
So the structure is simply a class for the object, with two lists for sub objects and sub properties. Each property has a name and a (list of) value(s). The only choice came from the collections: we chose to represent them as a kind
of object list nested inside a property: - the list correspond to the "<>" part
- the objects correspond to the the items, with the NAME and END
- each object of this object list has properties (NAME= VALUE)
This can be represented with the following diagram:
This picture has been build using our "delphi-like" picture editor (Palette,
Inspector, Design surface etc.). To be able to move, resize, save the figures, we use an in-memory structure. This structure can then be used to generate the corresponding unit, with the CLASSes.
In addition to the members and methods, we can also generate some standard CLASSes, like object lists using tList or tStringList. To detect which
CLASS should be generated from a List container, we can either simple check for the "_list" suffix, or use a more complex syntax with all kind of original / replacement parameters. In our case, we have a single kind of list, with only
the name of the object as a parameter, so the "_list" suffix rule is enough. Our starting skeletton is:
// 001 u_c_xxx_list
// 24 jan 2005
(*$r+*)
unit u_c_xxx_list;
interface
uses Classes, u_c_basic_object;
type c_xxx= // one "xxx"
Class(c_basic_object)
// -- m_name:
Constructor create_xxx(p_name: String);
function f_display_xxx: String;
function f_c_self: c_xxx;
Destructor Destroy; Override;
end; // c_xxx
c_xxx_list= // "xxx" list
Class(c_basic_object)
m_c_xxx_list: tStringList;
Constructor create_xxx_list(p_name: String);
function f_xxx_count: Integer;
function f_c_xxx(p_xxx_index: Integer): c_xxx;
function f_index_of_xxx(p_xxx_name: String): Integer;
function f_c_find_by_xxx(p_xxx_name: String): c_xxx;
procedure add_xxx(p_xxx_name: String; p_c_xxx: c_xxx);
function f_c_add_xxx(p_xxx_name: String): c_xxx;
function f_c_add_unique_xxx(p_xxx_name: String): c_xxx;
procedure display_xxx_list;
Destructor Destroy; Override;
end; // c_xxx_list
implementation
uses SysUtils, u_display;
// -- c_xxx
Constructor c_xxx.create_xxx(p_name: String);
begin
Inherited create_basic_object(p_name);
end; // create_xxx
function c_xxx.f_display_xxx: String;
begin
Result:= Format('%-10s ', [m_name]);
end; // f_display_xxx
function c_xxx.f_c_self: c_xxx;
begin
Result:= Self;
end; // f_c_self
Destructor c_xxx.Destroy;
begin
InHerited;
end; // Destroy
// -- c_xxx_list
Constructor c_xxx_list.create_xxx_list(p_name: String);
begin
Inherited create_basic_object(p_name);
m_c_xxx_list:= tStringList.Create;
end; // create_xxx_line
function c_xxx_list.f_xxx_count: Integer;
begin
Result:= m_c_xxx_list.Count;
end; // f_xxx_count
function c_xxx_list.f_c_xxx(p_xxx_index: Integer): c_xxx;
begin
Result:= c_xxx(m_c_xxx_list.Objects[p_xxx_index]);
end; // f_c_xxx
function c_xxx_list.f_index_of_xxx(p_xxx_name: String): Integer;
begin
Result:= m_c_xxx_list.IndexOf(p_xxx_name);
end; // f_index_of_xxx
function c_xxx_list.f_c_find_by_xxx(p_xxx_name: String): c_xxx;
var l_index_of: Integer;
begin
l_index_of:= f_index_of_xxx(p_xxx_name);
if l_index_of< 0
then Result:= Nil
else Result:= c_xxx(m_c_xxx_list.Objects[l_index_of]);
end; // f_c_find_by_name
procedure c_xxx_list.add_xxx(p_xxx_name: String; p_c_xxx: c_xxx);
begin
m_c_xxx_list.AddObject(p_xxx_name, p_c_xxx);
end; // add_xxx
function c_xxx_list.f_c_add_xxx(p_xxx_name: String): c_xxx;
begin
Result:= c_xxx.create_xxx(p_xxx_name);
m_c_xxx_list.AddObject(p_xxx_name, Result);
end; // f_c_add_xxx
function c_xxx_list.f_c_add_unique_xxx(p_xxx_name: String): c_xxx;
var l_index_of: Integer;
begin
l_index_of:= f_index_of_xxx(p_xxx_name);
if l_index_of>= 0
then Result:= f_c_xxx(l_index_of)
else Result:= f_c_add_xxx(p_xxx_name);
end; // f_c_add_unique_xxx
procedure c_xxx_list.display_xxx_list;
var l_xxx_index: Integer;
begin
display(m_name+ ' '+ IntToStr(f_xxx_count));
for l_xxx_index:= 0 to f_xxx_count- 1 do
display(f_c_xxx(l_xxx_index).f_display_xxx);
end; // display_xxx_list
Destructor c_xxx_list.Destroy;
var l_xxx_index: Integer;
begin
for l_xxx_index:= 0 to f_xxx_count- 1 do
f_c_xxx(l_xxx_index).Free;
m_c_xxx_list.Free;
Inherited;
end; // Destroy
begin // u_c_xxx_list
end. // |
By using the figure's data, the skeletton list and a simple generator, we get the unit which will represent the .Dfm's structure. After adding some members (not shown in the UML diagram), we then obtain the following definition:
c_dfm_object_list= Class; // forward
c_dfm_property= // one "property"
Class(c_basic_object)
// -- m_name: the property name
// -- if "Font.Color"
m_c_name_list: tStringList;
// -- if object tree, value "xxx= yyy.zzz" saved
// -- as 3 values "yyy" "." "zzz"
m_c_value_list: tStringList;
m_is_set: Boolean;
m_has_brace: Boolean;
m_is_list: Boolean;
m_is_collection: Boolean;
// -- modeled as an object list
m_c_dfm_collection_object_list: c_dfm_object_list;
m_property_type: t_dfm_symbol_type;
Constructor create_dfm_property(p_name: String);
function f_display_dfm_property: String;
function f_c_self: c_dfm_property;
procedure add_name(p_name: String);
procedure add_value(p_value: String);
procedure add_unique_value(p_value: String);
procedure update_property_type(p_property_type: t_dfm_symbol_type);
function f_display_value_list: String;
function f_display_tree_value_list: String;
function f_display_name_list: String;
Destructor Destroy; Override;
end; // c_dfm_property
c_dfm_property_list= // "property" list
Class(c_basic_object)
m_c_dfm_property_list: tStringList;
Constructor create_dfm_property_list(p_name: String);
function f_dfm_property_count: Integer;
function f_c_dfm_property(p_dfm_property_index: Integer): c_dfm_property;
function f_index_of(p_dfm_property_name: String): Integer;
function f_c_find_by_dfm_property(p_dfm_property_name: String): c_dfm_property;
procedure add_dfm_property(p_dfm_property_name: String; p_c_dfm_property: c_dfm_property);
function f_c_add_dfm_property(p_dfm_property_name: String): c_dfm_property;
function f_c_add_unique_dfm_property(p_dfm_property_name: String): c_dfm_property;
procedure display_dfm_property_list;
Destructor Destroy; Override;
end; // c_dfm_property_list
c_dfm_object= Class; // Forward
c_dfm_object_list= // "dfm_object" list
Class(c_basic_object)
m_c_dfm_object_list: tStringList;
m_is_collection: Boolean;
Constructor create_dfm_object_list(p_name: String);
function f_dfm_object_count: Integer;
function f_c_dfm_object(p_dfm_object_index: Integer): c_dfm_object;
function f_index_of(p_dfm_object_name: String): Integer;
function f_c_find_by_dfm_object(p_dfm_object_name: String): c_dfm_object;
procedure add_dfm_object(p_dfm_object_name: String; p_c_dfm_object: c_dfm_object);
function f_c_add_dfm_object(p_dfm_object_name: String): c_dfm_object;
function f_c_add_unique_dfm_object(p_dfm_object_name: String): c_dfm_object;
procedure display_dfm_object_list;
procedure display_dfm_object_and_properties;
Destructor Destroy; Override;
end; // c_dfm_object_list
c_dfm_object= // one "dfm_object"
Class(c_basic_object)
// -- m_name: the object name
m_object_name: String;
m_is_collection: Boolean;
m_c_dfm_object_list: c_dfm_object_list;
m_c_dfm_property_list: c_dfm_property_list;
Constructor create_dfm_object(p_name: String);
function f_display_dfm_object: String;
function f_c_self: c_dfm_object;
procedure display_dfm_object_tree;
// -- for comparision with scanned text
procedure save_to_txt(p_scanner_full_file_name, p_full_file_name: String);
// -- for "true" generation
procedure generate_indented_text(p_full_file_name: String);
Destructor Destroy; Override;
end; // c_dfm_object
|
The body of those classes, as well as the building of the the structure are in the companion .ZIP.
2.6 - Using the Parser To use the parser
2.7 - Why a parser ? Here are a couple of examples about how we use the parser:
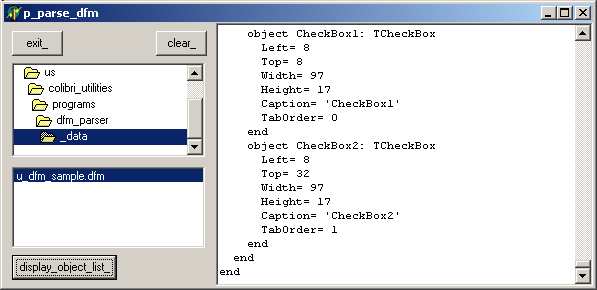
- to modify some .DFM's (removing or changing some properties). For instance, one of our customer requested the use of Quick Report. To my astonishment, you cannot resize some qrdbText or qrLabel without manually repositionning
the components to the right of the resized component. The parser was used to automatically recompute the components sizes: we simply start from the left, and adjust the Left by computing the previous Left plus the previous Width
- to create "stub components". Quick Report again: the components need a connection to a valid printer. The printer was on a network which was not always connected. So we built a "phoney quick report" component suite,
allowing us to still work with the parts which did not depend on the report layout.
- we also used the parser to shift from one Report generator to another. Guess who was involved once again ?
If such applications are of some interest to you, just send us a mail at fcolibri@felix-colibri.com, and we will try to publish some of the projects using the .dfm parser.
3 - Download the Sources Here are the source code files: - parse_dfm.zip: the project with the parser and the data structure (51 K)
The .ZIP file(s) contain:
- the main program (.DPR, .DOF, .RES), the main form (.PAS, .DFM), and any other auxiliary form
- any .TXT for parameters, samples, test data
- all units (.PAS) for units
Those .ZIP
- are self-contained: you will not need any other product (unless expressly mentioned).
- for Delphi 6 projects, can be used from any folder (the pathes are RELATIVE)
- will not modify your PC in any way beyond the path where you placed the .ZIP (no registry changes, no path creation etc).
To use the .ZIP: - create or select any folder of your choice
- unzip the downloaded file
- using Delphi, compile and execute
To remove the .ZIP simply delete the folder. The Pascal code uses the Alsacian notation, which prefixes identifier by
program area: K_onstant, T_ype, G_lobal, L_ocal, P_arametre, F_unction, C_lass etc. This notation is presented in the Alsacian Notation paper.
As usual:
- please tell us at fcolibri@felix-colibri.com if you found some errors, mistakes, bugs, broken links or had some problem downloading the file. Resulting corrections will
be helpful for other readers
- we welcome any comment, criticism, enhancement, other sources or reference suggestion. Just send an e-mail to fcolibri@felix-colibri.com.
- or more simply, enter your (anonymous or with your e-mail if you want an answer) comments below and clic the "send" button
- and if you liked this article, talk about this site to your fellow developpers, add a link to your links page ou mention our articles in your blog or newsgroup posts when relevant. That's the way we operate:
the more traffic and Google references we get, the more articles we will write.
4 - Conclusion We presented in this paper a simple parser which analyzes the content of a .Dfm
file, which is the starting point for many Delphi utilities.
5 - Other Papers with Source and Links
| Database | |
database reverse engineering | Extraction of the Database Schema by analyzing the content of the application's .DFMs
| | sql parser | Parsing SQL requests in Delphi, starting from an EBNF grammar for SELECT, INSERT and UPDATE |
| ado net tutorial |
a complete Ado Net architectural presentation, and projects for creating the Database, creating Tables, adding, deleting and updating rows, displaying the data in controls and DataGrids, using in memory DataSets, handling Views, updating the Tables with a DataGrid
| | turbo delphi interbase tutorial |
develop database applications with Turbo Delphi and Interbase. Complete ADO Net architecture, and full projects to create the database, the Tables, fill the rows, display and update the values with DataGrids. Uses the BDP |
| bdp ado net blobs | BDP and Blobs : reading and writing Blob fields using the BDP with Turbo Delphi |
| interbase stored procedure grammar |
Interbase Stored Procedure Grammar : The BNF Grammar of the Interbase Stored Procedure. This grammar can be used to build stored procedure utilities, like pretty printers, renaming tools, Sql Engine conversion or ports | |
using interbase system tables |
Using InterBase System Tables : The Interbase / FireBird System Tables: description of the main Tables, with their relationship and presents examples of how to extract information from the schema | |
eco tutorial |
Writing a simple ECO application: the UML model, the in memory objects and the GUI presentation. We also will show how to evaluate OCL expressions using the EcoHandles, and persist the data on disc | |
delphi dbx4 programming |
the new dbExpress 4 framework for RAD Studio 2007 : the configuration files, how to connect, read and write data, using tracing and pooling delegates and metadata handling | |
blackfishsql |
using the new BlackfishSql standalone database engine of RAD Studio 2007 (Win32 and .Net) : create the database, create / fill / read Tables, use Pascal User Defined Functions and Stored Procedures | |
rave pdf intraweb |
how to produce PDF reports using Rave, and have an Intraweb site generate and display .PDF pages, with multi-user access | |
embarcadero er studio |
Embarcadero ER Studio tutorial: how to use the Entity Relationship tool to create a new model, reverse engineer a database, create sub-models, generate reports, import metadata, switch to Dimensional Model | | |
| Web |
| sql to html | converting SQL ascii request to HTML format
| | simple web server |
a simple HTTP web Server and the corresponding HTTP web Browser, using our Client Server Socket library | |
simple cgi web server |
a simple CGI Web Server which handles HTML <FORM> requests, mainly for debugging CGI Server extension purposes | |
cgi database browser | a CGI extension in order to display and modify a Table using a Web Browser | |
whois | a Whois Client who requests information about owners of IP adresses. Works in batch mode. | |
web downloader |
an HTTP tool enabling to save on a local folder an HTML page with its associated images (.GIF, .JPEG, .PNG or other) for archieving or later off-line reading | |
web spider | a Web Spider allowing to download all pages from a site, with custom or GUI filtering and selection. | |
asp net log file |
a logging CLASS allowing to monitor the Asp.Net events, mainly used for undesrtanding, debugging and journaling Asp.Net Web applications | |
asp net viewstate viewer |
an ASP.NET utility displaying the content of the viewtate field which carries the request state between Internet Explorer and the IIS / CASSINI Servers | |
rss reader |
the RSS Reader lets you download and view the content of an .RSS feed (the entry point into somebody's blog) in a tMemo or a tTreeView. Comes complete with an .HTML downloader and an .XML parser | |
news message tree |
how to build a tree of the NNTP News Messages. The downloaded messages are displayed in tListBox by message thread (topic), and for each thread the messages are presented in a tTreeVi"ew | |
threaded indy news reader |
a NewsReader which presents the articles sorted by thread and in a logical hierarchical way. This is the basic Indy newsreader demo plus the tree organization of messages | |
delphi asp net portal programming |
presentation, architecture and programming of the Delphi Asp Net Portal. This is a Delphi version of the Microsoft ASP.NET Starter Kit Web Portal showcase. With detailed schemas and step by step presentation, the Sql scripts and binaries of the Database
| | delphi web designer |
a tiny Delphi "RAD Web Designer", which explains how the Delphi IDE can be used to generate .HTML pages using the Palette / Object Inspector / Form metaphor to layout the page content | |
intraweb architecture |
the architecture of the Intraweb web site building tool. Explains how Delphi "rad html generator" work, and presents the CLASS organization (UML Class diagrams) | |
ajax tutorial |
AJAX Tutorial : writing an AJAX web application. How AJAX works, using a JavaScript DOM parser, the Indy Web Server, requesting .XML data packets - Integrated development project | |
asp net master pages |
Asp.Net 2.0 Master Pages : the new Asp.Net 2.0 allow us to define the page structure in a hierarchical way using Master Pages and Content Pages, in a way similar to tForm inheritance |
| delphi asp net 20 databases |
Asp.Net 2.0 and Ado.Net 2.0 : displaying and writing InterBase and Blackfish Sql data using Dbx4, Ado.Net Db and AdoDbxClient. Handling of ListBox and GridView with DataSource components
| | asp net 20 users roles profiles |
Asp.Net 2.0 Security: Users, Roles and Profiles : Asp.Net 2.0 offers a vaslty improved support for handling security: new Login Controls, and services for managing Users, grouping Users in Roles, and storing User preferences in Profiles
| | bayesian spam filter |
Bayesian Spam Filter : presentation and implementation of a spam elimination tool which uses Bayesian Filtering techniques | | |
| TCP/IP | |
tcp ip sniffer | project to capture and display the packets travelling on the Ethernet network of your PC. | |
sniffing interbase traffic |
capture and analysis of Interbase packets. Creation of a database and test table, and comparison of the BDE vs Interbase Express Delphi components | |
socket programming | the simplest Client Server example of TCP / IP communication using Windows Sockets with Delphi |
| delphi socket architecture |
the organization of the ScktComp unit, with UML diagrams and a simple Client Server file transfer example using tClientSocket and tServerSocket | | |
| Object Oriented Programming Components |
| delphi virtual constructor |
VIRTUAL CONSTRUCTORS together with CLASS references and dynamic Packages allow the separation between a main project and modules compiled and linked in later. The starting point for Application Frameworks and Plugins
| | delphi generics tutorial |
Delphi Generics Tutorial : using Generics (parameterized types) in Delphi : the type parameter and the type argument, application of generics, constraints on INTERFACEs or CONSTRUCTORs | |
| | UML Patterns |
| the lexi editor |
delphi source code of the Gof Editor: Composite, Decorator, Iterator, Strategy, Visitor, Command, with UML diagrams | |
factory and bridge patterns |
presentation and Delphi sources for the Abstract Factory and Bridge patterns, used in the Lexi Document Editor case study from the GOF book | |
gof design patterns |
delphi source code of the 23 Gof (GAMMA and other) patterns: Composite, Decorator, Iterator, Strategy, Visitor, Command | | | |
| | Graphic |
| delphi 3d designer |
build a 3d volume list, display it in perspective and move the camera, the screen or the volumes with the mouse. | |
writing a flash player |
build your own ShockWave Flash movie Player, with pause, custom back and forward steps, snapshots, resizing. Designed for analyzing .SWF demos. | | |
| Utilities | |
the coliget search engine |
a Full Text Search unit allowing to find the files in a directory satisfying a complex string request (UML AND Delphi OR Patters) | |
treeview html help viewer |
Treeview .HTML Help Viewer : the use of a Treeview along with a WebBrowser to display .HTML files alows both structuring and ordering of the help topics. This tool was used to browse the Delphi PRISM Wiki help. | |
| | Delphi utilities |
| delphi net bdsproj |
structure and analysis of the .BDSPROJ file with the help of a small Delphi .XML parser | | dccil bat generator
| generation of the .BAT for the Delphi DCCIL command line compiler using the .BDSPROJ | | dfm parser |
a Delphi Project analyzing the .DFM file and building a memory representation. This can be used for transformations of the form components | |
dfm binary to text | a Delphi Project converting all .DFM file from a path from binary to ascii format |
| component to code |
generate the component creation and initialization code by analyzing the .DFM. Handy to avoid installing components on the Palette when examining new libraries | |
exe dll pe explorer |
presents and analyzes the content of .EXE and .DLL files. The starting point for extracting resources, spying .DLL function calls or injecting additional functionalities | |
dll and process viewer |
analyze and display the list of running processes, with their associated DLLs and Memory mapped files (Process Walker) | | |
| Controls | |
find memo | a tMemo with "find first", "find next", "sort", "save" capabilities | | |
| |
6 - The author
Felix John COLIBRI works at the Pascal Institute. Starting with Pascal in 1979, he then became involved with Object Oriented Programming, Delphi, Sql, Tcp/Ip, Html, UML. Currently, he is mainly
active in the area of custom software development (new projects, maintenance, audits, BDE migration, Delphi
Xe_n migrations, refactoring), Delphi Consulting and Delph
training. His web site features tutorials, technical papers about programming with full downloadable source code, and the description and calendar of forthcoming Delphi, FireBird, Tcp/IP, Web Services, OOP / UML, Design Patterns, Unit Testing training sessions.
|